搜索到
55
篇与
的结果
-
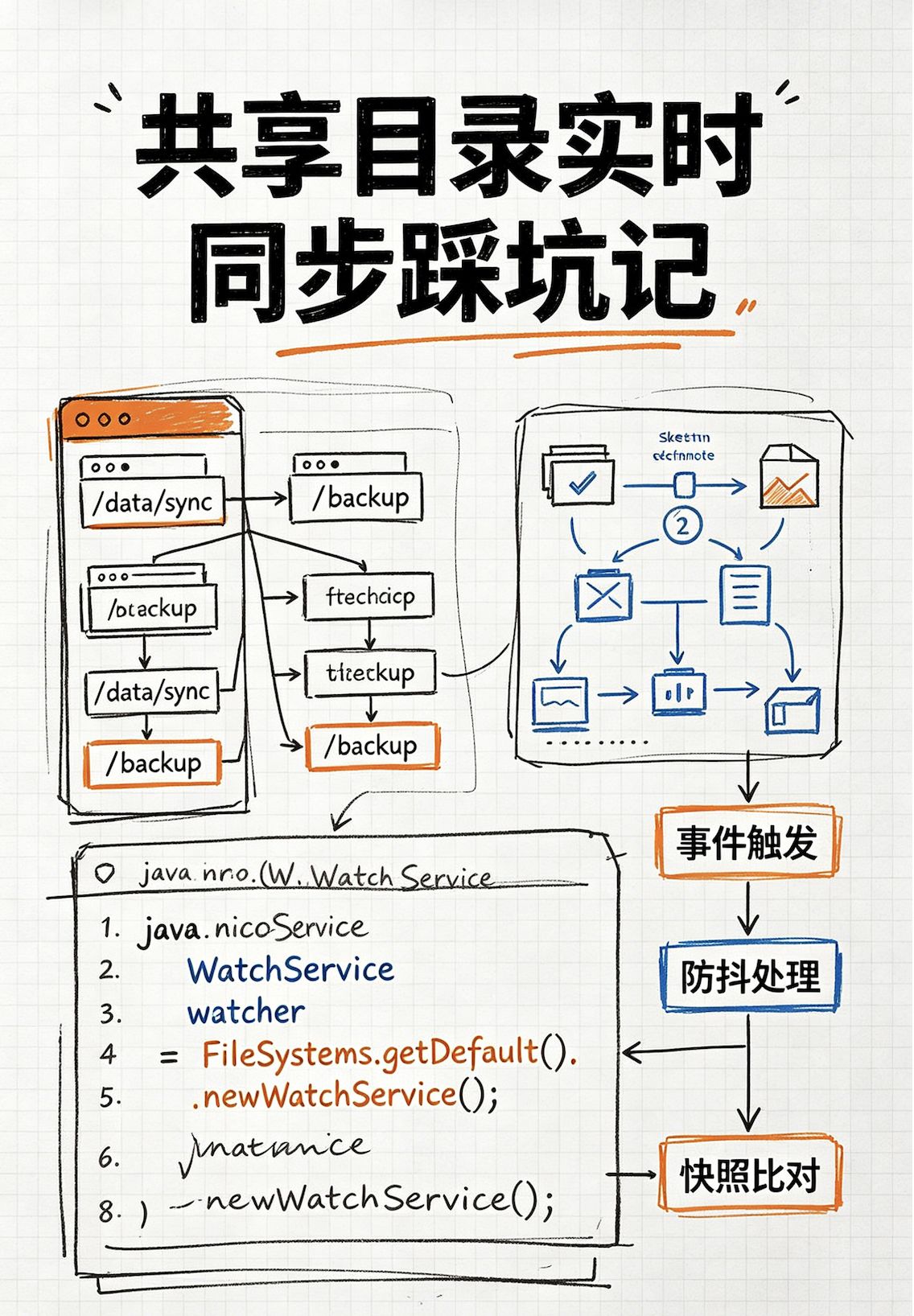
 做共享目录实时同步,踩过这些坑 项目背景:我们有一个知识库平台,之前都是用户在平台上上传文档,然后执行解析向量数据库,用于后续执行RAG现在客户希望可以文档上传到共享目录,系统就可以自动把这些文件同步到知识库。问题:为什么不用轮询?最直白的方案是定时扫目录,对比前后两次的文件列表差异。这个方案写起来简单,但有几个硬伤:延迟高:扫描周期设 5 分钟,用户上传后平均要等 2.5 分钟才能感知到IO 浪费:目录下文件多的时候,每次全量扫一遍磁盘开销不小无法感知"修改":如果只是文件内容变了但大小没变,很难准确判断所以决定用 java.nio.file.WatchService 做事件驱动监听。WatchService 的基本用法WatchService 本质上是对操作系统底层文件事件通知的封装。Linux 下用的是 inotify,Windows 下是 ReadDirectoryChangesW。注册一个目录的监听很简单:WatchService watchService = FileSystems.getDefault().newWatchService(); Path dir = Paths.get("/share"); WatchKey key = dir.register(watchService, ENTRY_CREATE, ENTRY_MODIFY, ENTRY_DELETE);然后在一个独立线程里 take() 阻塞等待事件:WatchKey key = watchService.take(); for (WatchEvent<?> event : key.pollEvents()) { // 处理事件 } key.reset(); // 必须 reset,否则后续事件收不到坑一:WatchService 不会递归监听子目录这是最容易被忽略的一点。dir.register(...) 只监听这一层目录,子目录下的文件变更完全收不到。我们的共享目录结构是 /share/知识库名/文件,层级不固定,用户还可能随时新建子目录。所以必须自己实现递归注册。方案是在启动时把整个目录树 walk 一遍,每个子目录都注册上:Files.walkFileTree(root, EnumSet.of(FileVisitOption.FOLLOW_LINKS), Integer.MAX_VALUE, new SimpleFileVisitor<>() { @Override public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException { register(dir); // 每个目录都注册监听 return FileVisitResult.CONTINUE; } });同时监听 ENTRY_CREATE 事件,当发现新建的是目录时,立刻给它补上注册:if (kind == ENTRY_CREATE && Files.isDirectory(child)) { registerAll(child); }坑二:目录创建时,里面的文件可能"漏事件"这是个很隐蔽的竞态条件。假设用户通过 cp -r 拷贝一整个目录进来,操作系统产生的事件顺序可能是:ENTRY_CREATE —— 新目录 /share/A/BENTRY_CREATE —— 目录下的文件 file1.txtENTRY_CREATE —— 目录下的文件 file2.txt但如果我们的处理逻辑在第 1 步给 /share/A/B 注册监听时稍微慢了一点,第 2、3 步的事件可能已经被操作系统发出,而我们还没注册上,于是漏掉了。解决办法是在注册新目录后,主动扫一遍目录里已有的文件,补发创建事件:if (Files.isDirectory(child)) { registerAll(child); emitCreateForExistingFiles(child); // 兜底补发 }private void emitCreateForExistingFiles(Path dir) { try (Stream<Path> pathStream = Files.walk(dir)) { pathStream.filter(Files::isRegularFile).forEach(eventHandler::onCreate); } }坑三:事件防抖文件写入往往不是原子操作。比如用户拷贝一个大文件,或者用户频繁修改文件,操作系统可能产生一连串的 MODIFY 事件。如果每个事件都触发一次上传,既浪费资源又容易出错。我们在事件处理器里加了基于时间窗口的去抖:String debounceKey = eventType + "|" + fullPath; long now = System.currentTimeMillis(); Long last = debounceMap.get(debounceKey); if (last != null && now - last < windowMillis) { return; // 同一个文件同类型事件,5 秒内只处理一次 } debounceMap.put(debounceKey, now);这里用 ConcurrentHashMap 保证线程安全,key 的设计是"事件类型 + 文件路径",这样创建和修改事件互不干扰。坑四:应用重启期间的事件丢失WatchService 是内存态的,应用一重启,期间发生的所有文件变更都感知不到了。这对于生产环境是不可接受的。我们的补偿方案是快照比对:每次补偿扫描时,把当前目录下所有文件的路径、大小、最后修改时间文件hash记录下来,存到 db下次扫描时加载上次的快照,和当前状态做 diff新出现的文件 → 补发 CREATE大小或修改时间变化的 → 补发 MODIFY快照里有但现在没了的 → 补发 DELETE快照存 MySQL 而不是本地文件,是为了在集群部署时也能共享状态(虽然当前是单实例,但预留了扩展空间)。补偿扫描有两个触发时机:启动时立即执行一次:覆盖重启期间的漏事件定时执行:默认 5 分钟一次,作为兜底@Scheduled(fixedDelayString = "${doc.share-sync.reconcile-delay-ms:300000}") public void scheduledReconcile() { reconcile("scheduled"); }整体架构整个同步模块拆成了四个组件,职责很清晰:组件职责ShareDirWatcher基于 WatchService 的实时监听,递归注册子目录ShareFileEventHandler事件去抖、路径解析(从文件路径反查知识库ID)、文件处理ShareDirReconcileJob停机补偿扫描,快照比对补发事件ShareFileSnapshotStore快照的持久化存储(MySQL)配置也做了开关控制,方便分阶段上线:doc: share-sync: enabled: true dry-run: true # 第一阶段只打日志,不真写 root-dir: /share settle-seconds: 5 # 防抖窗口 reconcile-delay-ms: 300000一些没写的细节OVERFLOW 事件:WatchService 可能因事件队列满而丢失事件,此时会收到一个 OVERFLOW 事件。我们的处理是直接跳过,依赖定时补偿扫描来修复。删除事件的路径:ENTRY_DELETE 事件发生时,文件已经没了,ev.context() 只能拿到文件名,不能判断它是不是目录。所以删除事件统一走 onDelete,由下游根据数据库记录判断之前是什么。重复上传风险: 监听程序和定时补偿程序同时发现新创建了文件,会出现重复上传的问题。处理方案是添加数据库唯一索引,直接从数据库兜底总结WatchService 来做文件监听是我目前实现的方案,递归注册、新目录兜底扫描、事件去抖、停机补偿,这几块缺一不可。第一阶段先跑 dry-run,把日志打全、路径解析逻辑验证清楚,第二阶段再放开真实写入,这样上线心里比较有底。
做共享目录实时同步,踩过这些坑 项目背景:我们有一个知识库平台,之前都是用户在平台上上传文档,然后执行解析向量数据库,用于后续执行RAG现在客户希望可以文档上传到共享目录,系统就可以自动把这些文件同步到知识库。问题:为什么不用轮询?最直白的方案是定时扫目录,对比前后两次的文件列表差异。这个方案写起来简单,但有几个硬伤:延迟高:扫描周期设 5 分钟,用户上传后平均要等 2.5 分钟才能感知到IO 浪费:目录下文件多的时候,每次全量扫一遍磁盘开销不小无法感知"修改":如果只是文件内容变了但大小没变,很难准确判断所以决定用 java.nio.file.WatchService 做事件驱动监听。WatchService 的基本用法WatchService 本质上是对操作系统底层文件事件通知的封装。Linux 下用的是 inotify,Windows 下是 ReadDirectoryChangesW。注册一个目录的监听很简单:WatchService watchService = FileSystems.getDefault().newWatchService(); Path dir = Paths.get("/share"); WatchKey key = dir.register(watchService, ENTRY_CREATE, ENTRY_MODIFY, ENTRY_DELETE);然后在一个独立线程里 take() 阻塞等待事件:WatchKey key = watchService.take(); for (WatchEvent<?> event : key.pollEvents()) { // 处理事件 } key.reset(); // 必须 reset,否则后续事件收不到坑一:WatchService 不会递归监听子目录这是最容易被忽略的一点。dir.register(...) 只监听这一层目录,子目录下的文件变更完全收不到。我们的共享目录结构是 /share/知识库名/文件,层级不固定,用户还可能随时新建子目录。所以必须自己实现递归注册。方案是在启动时把整个目录树 walk 一遍,每个子目录都注册上:Files.walkFileTree(root, EnumSet.of(FileVisitOption.FOLLOW_LINKS), Integer.MAX_VALUE, new SimpleFileVisitor<>() { @Override public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException { register(dir); // 每个目录都注册监听 return FileVisitResult.CONTINUE; } });同时监听 ENTRY_CREATE 事件,当发现新建的是目录时,立刻给它补上注册:if (kind == ENTRY_CREATE && Files.isDirectory(child)) { registerAll(child); }坑二:目录创建时,里面的文件可能"漏事件"这是个很隐蔽的竞态条件。假设用户通过 cp -r 拷贝一整个目录进来,操作系统产生的事件顺序可能是:ENTRY_CREATE —— 新目录 /share/A/BENTRY_CREATE —— 目录下的文件 file1.txtENTRY_CREATE —— 目录下的文件 file2.txt但如果我们的处理逻辑在第 1 步给 /share/A/B 注册监听时稍微慢了一点,第 2、3 步的事件可能已经被操作系统发出,而我们还没注册上,于是漏掉了。解决办法是在注册新目录后,主动扫一遍目录里已有的文件,补发创建事件:if (Files.isDirectory(child)) { registerAll(child); emitCreateForExistingFiles(child); // 兜底补发 }private void emitCreateForExistingFiles(Path dir) { try (Stream<Path> pathStream = Files.walk(dir)) { pathStream.filter(Files::isRegularFile).forEach(eventHandler::onCreate); } }坑三:事件防抖文件写入往往不是原子操作。比如用户拷贝一个大文件,或者用户频繁修改文件,操作系统可能产生一连串的 MODIFY 事件。如果每个事件都触发一次上传,既浪费资源又容易出错。我们在事件处理器里加了基于时间窗口的去抖:String debounceKey = eventType + "|" + fullPath; long now = System.currentTimeMillis(); Long last = debounceMap.get(debounceKey); if (last != null && now - last < windowMillis) { return; // 同一个文件同类型事件,5 秒内只处理一次 } debounceMap.put(debounceKey, now);这里用 ConcurrentHashMap 保证线程安全,key 的设计是"事件类型 + 文件路径",这样创建和修改事件互不干扰。坑四:应用重启期间的事件丢失WatchService 是内存态的,应用一重启,期间发生的所有文件变更都感知不到了。这对于生产环境是不可接受的。我们的补偿方案是快照比对:每次补偿扫描时,把当前目录下所有文件的路径、大小、最后修改时间文件hash记录下来,存到 db下次扫描时加载上次的快照,和当前状态做 diff新出现的文件 → 补发 CREATE大小或修改时间变化的 → 补发 MODIFY快照里有但现在没了的 → 补发 DELETE快照存 MySQL 而不是本地文件,是为了在集群部署时也能共享状态(虽然当前是单实例,但预留了扩展空间)。补偿扫描有两个触发时机:启动时立即执行一次:覆盖重启期间的漏事件定时执行:默认 5 分钟一次,作为兜底@Scheduled(fixedDelayString = "${doc.share-sync.reconcile-delay-ms:300000}") public void scheduledReconcile() { reconcile("scheduled"); }整体架构整个同步模块拆成了四个组件,职责很清晰:组件职责ShareDirWatcher基于 WatchService 的实时监听,递归注册子目录ShareFileEventHandler事件去抖、路径解析(从文件路径反查知识库ID)、文件处理ShareDirReconcileJob停机补偿扫描,快照比对补发事件ShareFileSnapshotStore快照的持久化存储(MySQL)配置也做了开关控制,方便分阶段上线:doc: share-sync: enabled: true dry-run: true # 第一阶段只打日志,不真写 root-dir: /share settle-seconds: 5 # 防抖窗口 reconcile-delay-ms: 300000一些没写的细节OVERFLOW 事件:WatchService 可能因事件队列满而丢失事件,此时会收到一个 OVERFLOW 事件。我们的处理是直接跳过,依赖定时补偿扫描来修复。删除事件的路径:ENTRY_DELETE 事件发生时,文件已经没了,ev.context() 只能拿到文件名,不能判断它是不是目录。所以删除事件统一走 onDelete,由下游根据数据库记录判断之前是什么。重复上传风险: 监听程序和定时补偿程序同时发现新创建了文件,会出现重复上传的问题。处理方案是添加数据库唯一索引,直接从数据库兜底总结WatchService 来做文件监听是我目前实现的方案,递归注册、新目录兜底扫描、事件去抖、停机补偿,这几块缺一不可。第一阶段先跑 dry-run,把日志打全、路径解析逻辑验证清楚,第二阶段再放开真实写入,这样上线心里比较有底。 -
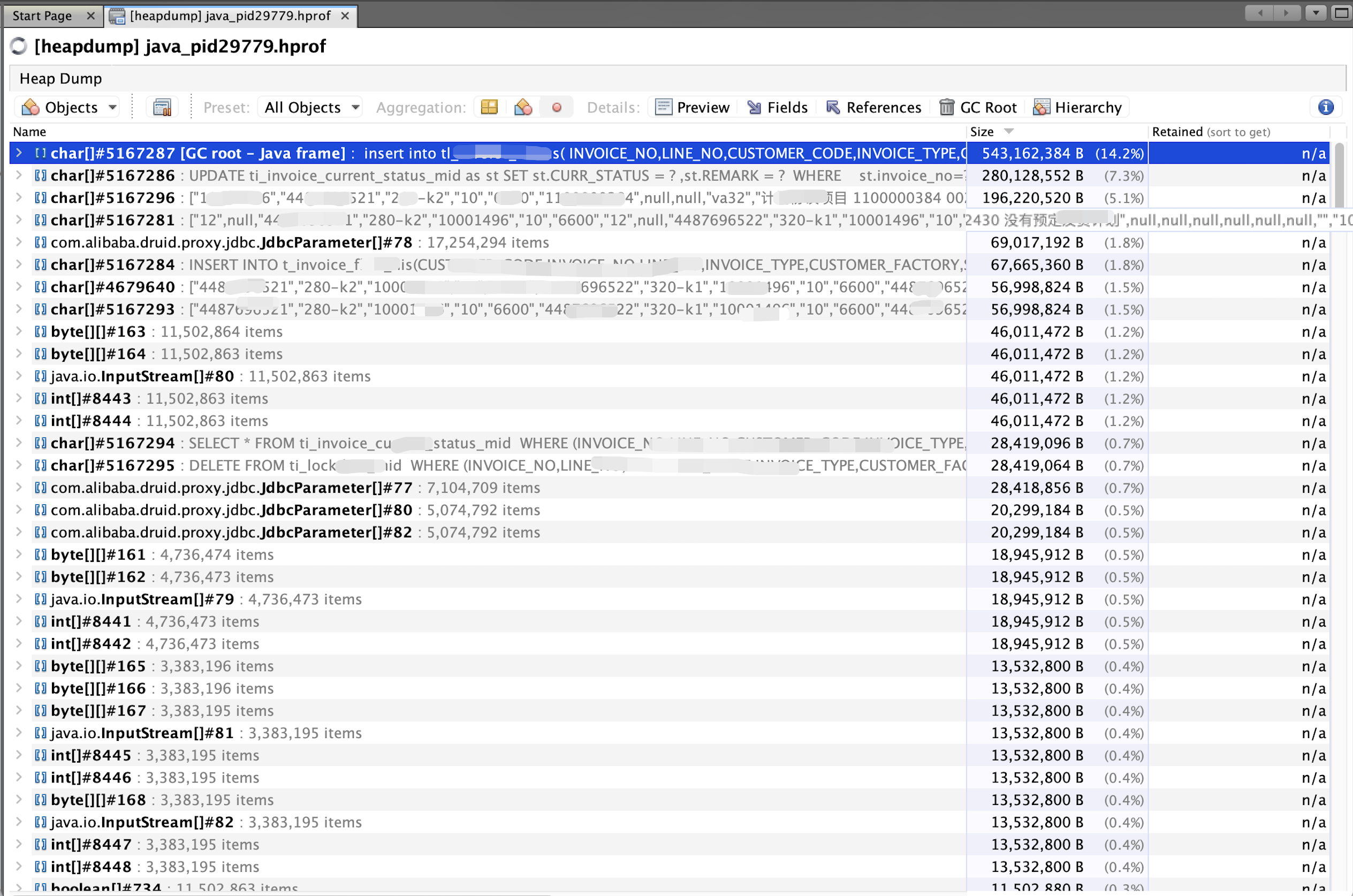
一次 OOM 线上排查实录 大家好,今天分享一次真实的线上 OOM 排查过程,踩坑 Druid 连接池的经典内存泄漏问题,以及完整的解决思路。一、问题现场:线上内存飙高,OOM 报警某天,线上老项目突然收到服务器内存使用率持续飙高的报警,紧接着应用直接抛出 OOM 错误,服务崩溃。紧急拉取了堆 Dump 文件,用 JProfiler 打开后,直接看到了内存占用的元凶:大量 com.alibaba.druid.proxy.jdbc 相关对象堆积堆中最大的单个对象是一个 char[],大小超过 500MB,存储的正是项目中执行的 SQL 字符串结合项目业务场景,初步判断是数据库操作相关的内存泄漏,定位方向直接锁定了代码中的 SQL 操作和 Druid 连接池配置。二、根因定位:双重问题叠加导致的灾难顺着堆 Dump 里的 SQL 文本,我直接定位到了业务代码,发现这次 OOM 是两个问题叠加导致的。1. 业务代码:SQL 拼接逻辑导致大对象堆积这是一个老项目,当年的开发同学已经离职了,代码里存在这样的逻辑:单条 INSERT 语句中,通过循环拼接 SQL 字符串,一次性插入大量数据当数据量较大时,拼接后的 SQL 字符串会变得非常大,生成的 char[] 对象直接占用几百 MB 内存这些大字符串被线程栈引用,短时间内无法被 GC 回收,直接推高了内存水位2. 框架层面:Druid 1.1.22 版本的经典 SQL 缓存泄漏堆 Dump 中大量的 Druid 对象,指向了一个更致命的问题:Druid 连接池的 SQL 统计缓存。项目使用的 Druid 版本是 1.1.22,这个版本存在一个广为人知的问题:SQL 统计功能会无限制缓存所有执行过的 SQL 字符串,无法自动清理项目中拼接的大量不同 SQL,会被 Druid 全部缓存到 sqlStatMap 中,这些对象会一直持有 SQL 字符串的引用,导致它们无法被 GC 回收随着服务运行时间增长,缓存的 SQL 越来越多,内存只会涨不会跌,最终撑满堆内存,触发 OOM三、解决方案:两步走彻底根治问题针对这两个问题,我们采用了业务+框架双管齐下的修复方案,从根源解决内存泄漏。第一步:优化 Druid 配置,掐断缓存泄漏直接修改项目的 Druid 配置,关闭无限制的 SQL 统计,同时限制缓存大小,避免内存无限增长。方案 A:彻底关闭 SQL 统计(推荐,零泄漏风险)spring: datasource: druid: filter: stat: enabled: false # 关闭导致内存泄漏的SQL统计 web-stat-filter: enabled: false # 关闭Web统计,减少额外内存占用方案 B:保留监控,限制缓存大小(折中方案)如果业务必须保留 SQL 监控,可以通过配置限制缓存的 SQL 数量,避免无限增长:spring: datasource: druid: filter: stat: enabled: true max-stat-count: 200 # 限制最多缓存200条SQL,超出自动淘汰第二步:重构业务代码,替换 SQL 拼接为批量插入修改原有的 SQL 拼接逻辑,改为标准的批量插入方式,既避免了超大 SQL 字符串的生成,也提升了数据库写入性能。改造前(问题代码)// 循环拼接SQL,生成超大字符串 StringBuilder sql = new StringBuilder("INSERT INTO t_invoice (col1, col2) VALUES "); for (Invoice invoice : list) { sql.append("(?, ?),"); } jdbcTemplate.update(sql.toString(), params);改造后(批量插入)// 使用JdbcTemplate批量插入,避免生成超大SQL字符串 String sql = "INSERT INTO t_invoice (col1, col2) VALUES (?, ?)"; jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() { @Override public void setValues(PreparedStatement ps, int i) throws SQLException { ps.setString(1, list.get(i).getCol1()); ps.setString(2, list.get(i).getCol2()); } @Override public int getBatchSize() { return list.size(); } });四、效果验证与后续优化改造完成后,我们重新上线服务并进行了压测验证:内存曲线恢复平稳,不再出现持续飙高的情况堆 Dump 中 Druid 相关对象和大 char[] 基本消失数据库写入性能也有明显提升,单批次插入耗时降低了 40%额外优化建议对于老项目,建议升级 Druid 到最新稳定版(如 1.2.20+),修复了大量已知的内存泄漏问题批量插入时,建议设置合理的批次大小(如每批 100-500 条),避免单次操作过大导致数据库压力上线前务必进行压测,通过 JProfiler 或 Arthas 观察内存变化,提前发现潜在问题五、踩坑总结这次 OOM 排查给了我两个深刻的教训:老项目的依赖版本一定要关注:Druid 1.1.22 这个版本的 SQL 缓存泄漏问题非常普遍,很多线上 OOM 都源于此,升级或关闭统计是最直接的解决方式。业务代码的 SQL 拼接是隐形杀手:不仅容易导致 SQL 注入,还会生成超大对象,配合框架的缓存机制,很容易引发内存泄漏。批量插入是更安全、更高效的替代方案。希望这次分享能帮到遇到同样问题的朋友,如果你也遇到了 Druid 相关的内存问题,欢迎在评论区交流讨论~
-
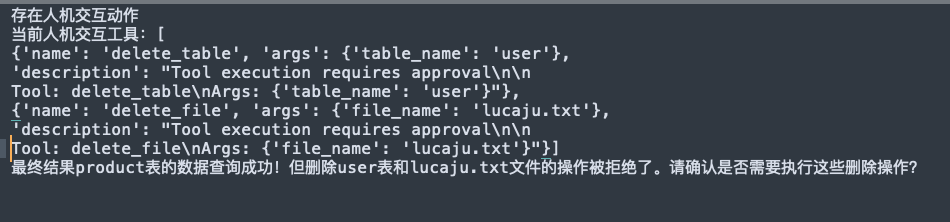
DeepAgents 人工介入实战|LangGraph 实现 Agent 高危工具人工审批 之前一篇文章里,我使用 Spring AI Alibaba 演示了智能体执行过程中的人工介入能力。那篇文章的核心思路是:当 Agent 准备执行某些高风险动作时,不要让它直接执行,而是先暂停下来,把待执行动作交给人工审批,审批通过后再继续执行。感兴趣的小伙伴可以通过下面链接回顾一下:https://www.lucaju.cn/index.php/archives/165/这篇文章换一个技术栈,使用 Python 版本来实现同样的能力。本次示例基于:LangChain:负责模型和工具抽象LangGraph:负责执行状态、检查点和恢复执行DeepAgents:负责创建支持工具调用和中断审批的 Agent通义千问兼容 OpenAI API:作为底层大模型一、为什么 Agent 需要人工介入Agent 最大的价值是可以根据用户目标自主规划并调用工具。但并不是所有工具都适合完全自动执行。比如:删除数据库表删除文件发起转账修改线上配置调用外部系统执行不可逆操作这些动作一旦执行错误,影响可能非常大。所以比较合理的模式是:普通查询类动作可以让 Agent 自动执行,高风险动作必须先进入人工审批。在本文示例中,我们定义了三个工具:query_table_data:查询表数据,低风险,可以自动执行delete_table:删除数据表,高风险,需要人工审批delete_file:删除文件,高风险,需要人工审批用户输入的任务是:先查询product表的数据!再删除user表,最后,删除lucaju.txt文件Agent 会先分析任务,并尝试依次调用工具。但当执行到删除表、删除文件这类高风险动作时,会被框架中断,等待人工确认。二、初始化大模型首先初始化模型:import os from langchain.chat_models import init_chat_model llm = init_chat_model( model="kimi-k2.5", model_provider="openai", api_key=os.getenv("AliQwen_API"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model_kwargs={"reasoning_effort": "none"}, )这里使用的是 OpenAI 兼容模式,所以 model_provider 设置为 openai,同时把 base_url 指向阿里云 DashScope 的兼容接口。需要提前配置环境变量:export AliQwen_API="你的 API Key"model_kwargs={"reasoning_effort": "none"} 是模型调用参数,可以根据实际模型支持情况调整。三、定义工具示例中定义了三个工具:from langchain.tools import tool @tool def delete_table(table_name: str) -> str: """ 删除指定的表 """ return f"删除表{table_name}" @tool def delete_file(file_name: str) -> str: """ 删除指定的文件 """ return f"删除文件{file_name}" @tool def query_table_data(table_name: str) -> str: """ 查询指定表的数据 """ return f"查询表{table_name}的数据"这里为了演示效果,工具内部只是返回字符串,并没有真的连接数据库或删除文件。在真实项目中,delete_table 可能会执行 SQL,delete_file 可能会操作对象存储或服务器文件系统。这类工具就非常适合加人工审批。四、为什么必须配置 CheckpointerHuman-in-the-loop 的核心不是简单地打印一句“是否确认”,而是让 Agent 的执行流程真正暂停下来,并且后续可以从暂停点继续执行。这就需要保存执行状态。示例代码中使用了 LangGraph 提供的内存检查点:from langgraph.checkpoint.memory import InMemorySaver checkpointer = InMemorySaver() config = { "configurable": { "thread_id": "123" } }这里有两个关键点:checkpointer 用来保存 Agent 的执行状态。thread_id 用来标识当前会话。当 Agent 执行到需要人工介入的节点时,LangGraph 会把当前状态保存下来。等人工审批完成后,再通过同一个 thread_id 找回之前的状态,并继续执行。如果没有检查点,框架就不知道应该从哪里恢复执行。五、创建支持人工介入的 DeepAgent接下来创建 Agent:from deepagents import create_deep_agent main_agent = create_deep_agent( model=llm, name="主智能体", system_prompt="回答使用中文,调用对应的工具实现对应的功能!", tools=[delete_table, delete_file, query_table_data], interrupt_on={"delete_table": True, "delete_file": True}, checkpointer=checkpointer )这里最关键的是两个参数:interrupt_on={"delete_table": True, "delete_file": True}以及:checkpointer=checkpointerinterrupt_on 用来声明哪些工具调用需要中断。在这个例子中:调用 query_table_data 不会中断调用 delete_table 会中断调用 delete_file 会中断也就是说,Agent 可以自动查询数据,但不能自动删除表或文件。这就是人工介入的核心配置。六、第一次执行:触发中断第一次执行 Agent:result_1 = main_agent.invoke( { "messages": [ { "role": "user", "content": "先查询product表的数据!再删除user表,最后,删除lucaju.txt文件", } ] }, config=config, )这次调用并不一定会完整执行完所有工具。如果执行链路中包含需要人工审批的工具,Agent 会暂停,并把中断信息放到返回结果的 __interrupt__ 字段中。示例代码中这样获取:interrupt = result_1["__interrupt__"]当 interrupt 不为空时,说明当前执行过程中存在需要人工介入的动作。七、查看待审批动作__interrupt__ 中会包含本次待审批的工具调用信息,例如:[ Interrupt( value={ "action_requests": [ { "name": "delete_table", "args": {"table_name": "user"}, "description": "Tool execution requires approval..." }, { "name": "delete_file", "args": {"file_name": "zhaoweifeng.txt"}, "description": "Tool execution requires approval..." } ], "review_configs": [ { "action_name": "delete_table", "allowed_decisions": ["approve", "edit", "reject"] }, { "action_name": "delete_file", "allowed_decisions": ["approve", "edit", "reject"] } ] } ) ]这里有两个比较重要的字段。action_requests 表示 Agent 想要执行哪些工具:工具名称工具参数工具描述review_configs 表示这些动作允许哪些审批结果:approve:同意执行edit:修改参数后执行reject:拒绝执行这三个动作基本覆盖了常见的人审场景。八、人工审批:拒绝高危操作示例代码中把删除表和删除文件都拒绝掉:decisions = [] action_requests = interrupt[0].value["action_requests"] print(f"当前人机交互工具:{action_requests}") for action_request in action_requests: if action_request["name"] == "delete_table": decisions.append({"type": "reject"}) elif action_request["name"] == "delete_file": decisions.append({"type": "reject"})这里的 decisions 顺序需要和 action_requests 对应。也就是说,如果 Agent 申请了两个动作:删除 user 表删除 zhaoweifeng.txt 文件那么人工审批结果也应该按顺序给出两个 decision。在这个示例中,两个高风险动作都被拒绝:[ {"type": "reject"}, {"type": "reject"} ]九、第二次执行:恢复 Agent审批完成后,不需要重新传入用户消息,而是通过 Command(resume=...) 恢复执行:from langgraph.types import Command result_2 = main_agent.invoke( Command( resume={ "decisions": decisions } ), config=config, )这里一定要继续传入相同的 config,尤其是相同的 thread_id。因为 Agent 要根据 thread_id 找到之前暂停的执行状态。恢复执行后,框架会根据人工审批结果继续处理:被 approve 的工具会继续执行被 reject 的工具不会执行被 edit 的工具会使用人工修改后的参数执行最后输出结果:print(f"最终结果{result_2['messages'][-1].content}")十、完整代码完整示例代码如下:""" 演示human-in-the-loop模式, 必须使用记忆功能 """ import os from deepagents import create_deep_agent from langchain.chat_models import init_chat_model from langchain.tools import tool from langgraph.checkpoint.memory import InMemorySaver from langgraph.types import Command # 初始化大模型 llm = init_chat_model( model="kimi-k2.5", model_provider="openai", api_key=os.getenv("AliQwen_API"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model_kwargs={"reasoning_effort": "none"}, ) # 删除表工具 @tool def delete_table(table_name: str) -> str: """ 删除指定的表 """ return f"删除表{table_name}" # 删除文件 @tool def delete_file(file_name: str) -> str: """ 删除指定的文件 """ return f"删除文件{file_name}" # 查询表数据 @tool def query_table_data(table_name: str) -> str: """ 查询指定表的数据 """ return f"查询表{table_name}的数据" # 设置检查点 checkpointer = InMemorySaver() # 配置检查点 config = { "configurable": { "thread_id": "123" } } # 创建deepagent,同时给高危工具设置人机交互 main_agent = create_deep_agent( model=llm, name="主智能体", system_prompt="回答使用中文,调用对应的工具实现对应的功能!", tools=[delete_table, delete_file, query_table_data], interrupt_on={"delete_table": True, "delete_file": True}, checkpointer=checkpointer ) # 预执行,本次不会真正的执行所有工具。 # 如果执行链路中存在人机交互节点,框架会暂停,并返回 __interrupt__。 result_1 = main_agent.invoke( { "messages": [ { "role": "user", "content": "先查询product表的数据!再删除user表,最后,删除lucaju.txt文件", } ] }, config=config, ) # 检查本次执行是否存在人机交互动作 interrupt = result_1["__interrupt__"] if interrupt: print("存在人机交互动作") # 定义一个列表,存储所有审批结果 decisions = [] # 获取所有待审批动作 action_requests = interrupt[0].value["action_requests"] print(f"当前人机交互工具:{action_requests}") for action_request in action_requests: if action_request["name"] == "delete_table": decisions.append({"type": "reject"}) elif action_request["name"] == "delete_file": decisions.append({"type": "reject"}) # 再次执行,不需要传会话内容,只需要传审批意见和 config result_2 = main_agent.invoke( Command( resume={ "decisions": decisions } ), config=config, ) print(f"最终结果{result_2['messages'][-1].content}")十一、如果想修改参数后再执行除了直接拒绝,我们也可以修改工具参数后再执行。比如 Agent 原本想删除:zhaoweifeng.txt人工审批时可以把文件名改成另一个值:decisions.append({ "type": "edit", "edited_action": { "name": action_request["name"], "args": { "file_name": "new-file.txt" } } })这时框架不会使用 Agent 原始生成的参数,而是使用人工编辑后的参数继续执行工具。这在实际业务中非常有用。例如:Agent 选择的表名不准确,人工改成正确表名Agent 生成的文件路径不安全,人工改成允许路径Agent 生成的金额过大,人工改成合理金额Agent 生成的收件人错误,人工改成正确收件人相比简单的同意或拒绝,edit 让人工介入更灵活。十二、执行流程总结整体流程可以概括为:用户输入任务 ↓ Agent 分析任务并规划工具调用 ↓ 普通工具自动执行 ↓ 遇到 interrupt_on 配置的高风险工具 ↓ LangGraph 保存状态并中断执行 ↓ 人工读取 __interrupt__ 中的 action_requests ↓ 人工给出 approve / edit / reject ↓ 使用 Command(resume=...) 恢复执行 ↓ Agent 根据审批结果继续完成任务这套机制的关键点是:interrupt_on:定义哪些工具需要人工审批checkpointer:保存执行状态thread_id:标识同一次会话__interrupt__:获取待审批动作Command(resume=...):把审批结果送回 Agent 并恢复执行十三、和 Spring AI Alibaba 版本的对比从思想上看,Python 版本和 Spring AI Alibaba 版本是一致的:Agent 不应该无限制地自动执行所有动作,高风险动作需要进入人工审批流程。但实现方式上有所不同。Spring AI Alibaba 更偏向 Java 生态,适合和 Spring Boot、企业系统、审批流、权限体系结合。而 LangChain + LangGraph + DeepAgents 的 Python 方案更偏向实验、原型验证和 Agent 工作流编排。尤其是 LangGraph 的 checkpoint 和 resume 机制,让“暂停后恢复”这件事变得非常自然。如果项目本身是 Java 技术栈,可以优先考虑 Spring AI Alibaba。如果项目本身是 Python 技术栈,或者正在做 Agent 编排、工具调用、多步骤任务规划,那么 DeepAgents 这套方式会比较顺手。十四、真实项目中的建议在真实项目中使用人工介入时,建议注意以下几点。第一,高风险工具要显式配置。不要只依赖 prompt 告诉模型“删除前要确认”。更可靠的方式是像本文一样,在框架层面对工具进行拦截。第二,审批信息要完整展示。人工审批时至少要看到:工具名称工具参数Agent 为什么要执行这个工具当前用户是谁当前会话上下文第三,审批结果要落库。生产环境中,审批记录应该持久化,包括:谁审批的什么时间审批的原始参数是什么修改后的参数是什么最终是通过、拒绝还是编辑后通过第四,检查点不要只用内存。本文为了演示使用的是:InMemorySaver()生产环境更建议使用数据库、Redis 或其他持久化存储。否则服务重启后,暂停中的 Agent 状态会丢失。第五,审批权限要和业务系统打通。不是所有人都应该可以批准所有工具调用。比如:普通用户只能审批自己的任务管理员可以审批团队任务涉及资金、删除、发布的动作需要更高权限人工介入不是简单的弹窗确认,而应该是完整的安全控制链路。关于DeepAgents的练习代码已经上传到了我的GitHub,欢迎fork & starhttps://github.com/Jucunqi/deepagents-practice.git
-
-
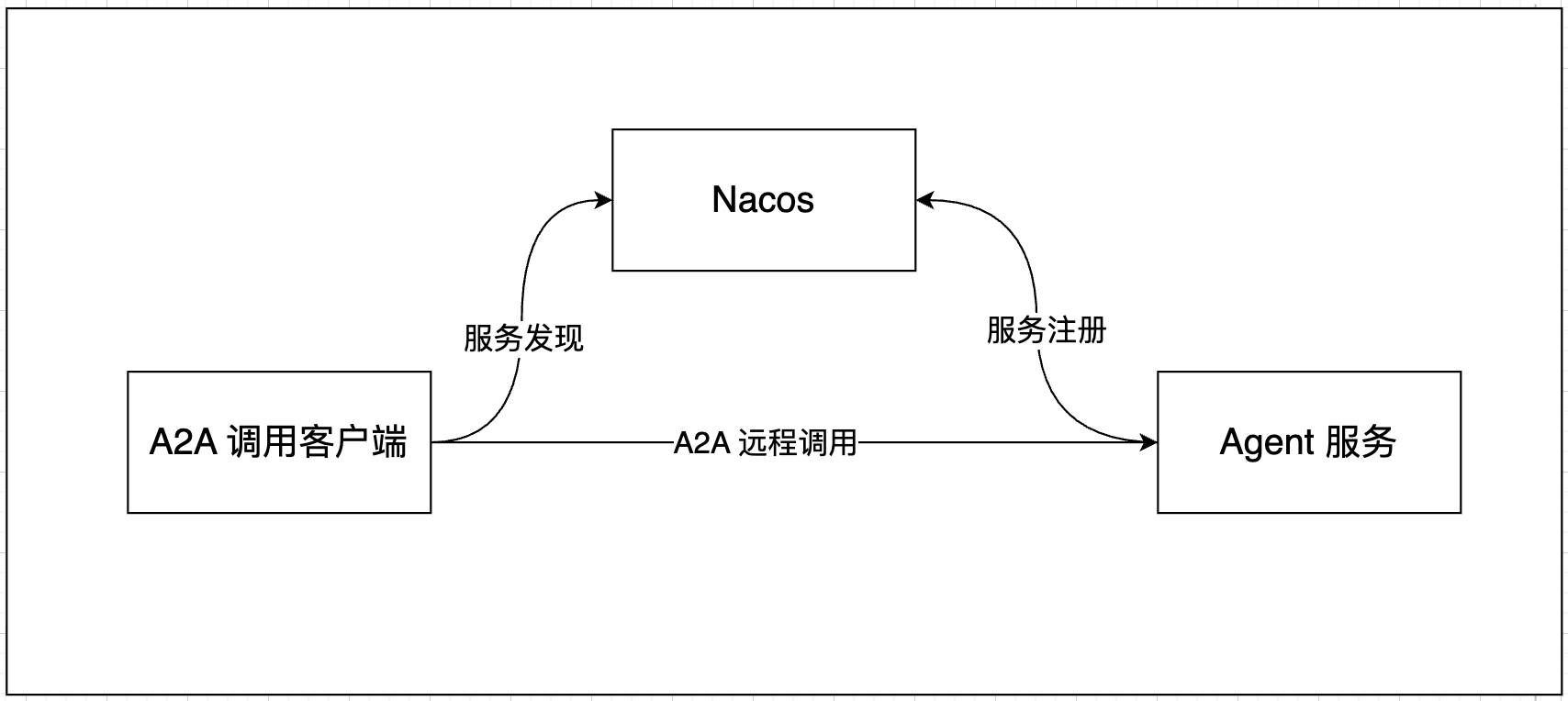
分布式智能体|A2A Agent实战 随着智能体应用的广泛应用,智能体的分布式部署、跨网络、跨框架、跨组织调用,成为当下智能体落地急需解决的问题。针对这一痛点,Google推出了Agent2Agent(简称A2A)协议,专为智能体之间的互联互通、协同协作提供标准化的解决方案。本文基于Spring AI Alibaba框架,使用Nacos作为注册中心,落地完整的分布式智能体方案。整体架构:一、Nacos注册中心安装本次选用的Nacos版本为3.2.0,安装配置流程可参考官方文档,这里不再赘述基础安装步骤。Nacos官方地址:https://nacos.io/二、项目依赖引入使用官方推荐的BOM方式进行依赖管理<dependencyManagement> <dependencies> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-bom</artifactId> <version>1.1.2.0</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>1.1.2</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-extensions-bom</artifactId> <version>1.1.2.2</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!-- 智能体核心框架 --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-agent-framework</artifactId> </dependency> <!-- 通义千问AI模型依赖 --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-dashscope</artifactId> </dependency> <!-- A2A+Nacos集成依赖 --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-a2a-nacos</artifactId> </dependency> </dependencies> 三、Agent服务注册配置完成依赖引入后,需要将自定义的智能体交由Spring容器管理,同时配置Nacos注册参数,实现智能体的自动注册。1. 配置Bean对象本次以讲笑话的智能体jokeAgent为例@Configuration public class A2AAgentConfig { @Bean(name = "jokeAgent") public ReactAgent jokeAgent() { // 构建通义千问API对象 DashScopeApi dashScopeApi = DashScopeApi.builder() .apiKey(System.getenv("AliQwen_API")) .build(); // 初始化对话模型 DashScopeChatModel chatModel = DashScopeChatModel.builder() .dashScopeApi(dashScopeApi) .defaultOptions(DashScopeChatOptions.builder() .model(DashScopeChatModel.DEFAULT_MODEL_NAME) .temperature(0.5) .maxToken(1000) .build()) .build(); // 创建并返回笑话智能体 return ReactAgent.builder() .name("jokeAgent") .model(chatModel) .description("负责讲笑话。") .instruction("你是一个幽默风趣、反应敏捷的笑话智能体。你的任务是根据用户的要求,讲一个轻松、健康、积极向上的短笑话。") .build(); } }2. 修改application.yml配置文件spring: application: name: spring-ai-alibaba-a2a-server ai: dashscope: api-key: ${AliQwen_API} alibaba: a2a: nacos: server-addr: 127.0.0.1:8848 username: nacos password: nacos registry: enabled: true # 启用服务注册(注册本地 Agent) server: version: 1.0.0 card: name: jokeAgent # 必须与Bean名称一致 description: 专门讲笑话的智能体3. 注册成功校验启动项目后,控制台出现如下日志,即代表智能体成功注册到Nacos注册中心:Auto register agent jokeAgent into Registry Nacos[127.0.0.1:8848] successfully.配置成功后在Nacos Console上面可以看到智能体成功注册四、Agent远程调用完成服务端智能体注册后,客户端即可通过A2A协议远程调用注册好的智能体,实现分布式跨服务的智能体协作。1. 客户端依赖准备客户端同样需要添加上述的A2A依赖2. 远程调用代码编写客户端调用代码如下@RestController public class RemoteAgentController { @Resource private AgentCardProvider agentCardProvider; @GetMapping("test") public void test() throws GraphRunnerException { // 服务发现:通过AgentCardProvider 从注册中心获取Agent A2aRemoteAgent remoteAgent = A2aRemoteAgent.builder() .name("jokeAgent") .agentCardProvider(agentCardProvider) .description("可以给我讲笑话") .build(); Optional<OverAllState> result = remoteAgent.invoke("请给我讲一个关于小明的笑话"); result.ifPresent(state -> System.out.println(state.data().get("output"))); } }3. 调用效果展示哈哈,收到指令——已启动「快乐多巴胺发射器」,正在加载健康笑点模块…滴!加载完毕!😄 来一个新鲜出炉的短笑话: > 为什么瑜伽垫从不参加辩论赛? > ——因为它信奉:**“不争、不抢、但能稳稳地托住你的人生起伏!”** 🧘♂️✨ > (温馨提示:它还默默提醒你——深呼吸3秒,肩膀放松,嘴角上扬5度…这波健康buff,免费续杯!) 需要再来一个?或者想指定主题(比如职场、早餐、遛狗、和Wi-Fi斗智斗勇…)?我库存里还有“无糖版”“低卡路里版”“含维生素C的笑果”哦~ 😎总结以上就是借助Spring AI Alibaba框架搭配Nacos注册中心,基于A2A协议可以快速实现分布式智能体的服务注册与远程调用的代码啦。源码已上传GitHub:https://github.com/Jucunqi/spring-ai-alibaba-agent.git