搜索到
20
篇与
的结果
-
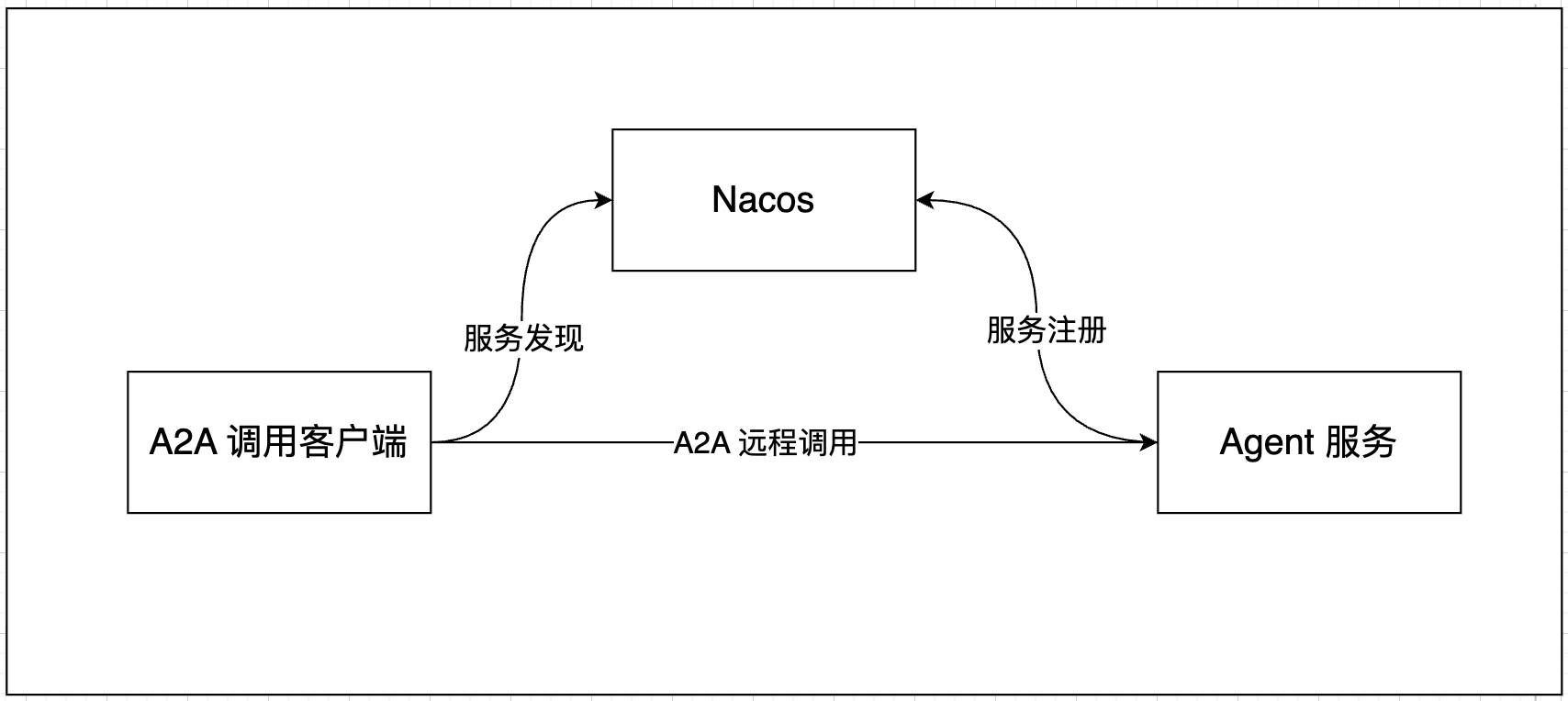
 分布式智能体|A2A Agent实战 随着智能体应用的广泛应用,智能体的分布式部署、跨网络、跨框架、跨组织调用,成为当下智能体落地急需解决的问题。针对这一痛点,Google推出了Agent2Agent(简称A2A)协议,专为智能体之间的互联互通、协同协作提供标准化的解决方案。本文基于Spring AI Alibaba框架,使用Nacos作为注册中心,落地完整的分布式智能体方案。整体架构:一、Nacos注册中心安装本次选用的Nacos版本为3.2.0,安装配置流程可参考官方文档,这里不再赘述基础安装步骤。Nacos官方地址:https://nacos.io/二、项目依赖引入使用官方推荐的BOM方式进行依赖管理<dependencyManagement> <dependencies> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-bom</artifactId> <version>1.1.2.0</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>1.1.2</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-extensions-bom</artifactId> <version>1.1.2.2</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!-- 智能体核心框架 --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-agent-framework</artifactId> </dependency> <!-- 通义千问AI模型依赖 --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-dashscope</artifactId> </dependency> <!-- A2A+Nacos集成依赖 --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-a2a-nacos</artifactId> </dependency> </dependencies> 三、Agent服务注册配置完成依赖引入后,需要将自定义的智能体交由Spring容器管理,同时配置Nacos注册参数,实现智能体的自动注册。1. 配置Bean对象本次以讲笑话的智能体jokeAgent为例@Configuration public class A2AAgentConfig { @Bean(name = "jokeAgent") public ReactAgent jokeAgent() { // 构建通义千问API对象 DashScopeApi dashScopeApi = DashScopeApi.builder() .apiKey(System.getenv("AliQwen_API")) .build(); // 初始化对话模型 DashScopeChatModel chatModel = DashScopeChatModel.builder() .dashScopeApi(dashScopeApi) .defaultOptions(DashScopeChatOptions.builder() .model(DashScopeChatModel.DEFAULT_MODEL_NAME) .temperature(0.5) .maxToken(1000) .build()) .build(); // 创建并返回笑话智能体 return ReactAgent.builder() .name("jokeAgent") .model(chatModel) .description("负责讲笑话。") .instruction("你是一个幽默风趣、反应敏捷的笑话智能体。你的任务是根据用户的要求,讲一个轻松、健康、积极向上的短笑话。") .build(); } }2. 修改application.yml配置文件spring: application: name: spring-ai-alibaba-a2a-server ai: dashscope: api-key: ${AliQwen_API} alibaba: a2a: nacos: server-addr: 127.0.0.1:8848 username: nacos password: nacos registry: enabled: true # 启用服务注册(注册本地 Agent) server: version: 1.0.0 card: name: jokeAgent # 必须与Bean名称一致 description: 专门讲笑话的智能体3. 注册成功校验启动项目后,控制台出现如下日志,即代表智能体成功注册到Nacos注册中心:Auto register agent jokeAgent into Registry Nacos[127.0.0.1:8848] successfully.配置成功后在Nacos Console上面可以看到智能体成功注册四、Agent远程调用完成服务端智能体注册后,客户端即可通过A2A协议远程调用注册好的智能体,实现分布式跨服务的智能体协作。1. 客户端依赖准备客户端同样需要添加上述的A2A依赖2. 远程调用代码编写客户端调用代码如下@RestController public class RemoteAgentController { @Resource private AgentCardProvider agentCardProvider; @GetMapping("test") public void test() throws GraphRunnerException { // 服务发现:通过AgentCardProvider 从注册中心获取Agent A2aRemoteAgent remoteAgent = A2aRemoteAgent.builder() .name("jokeAgent") .agentCardProvider(agentCardProvider) .description("可以给我讲笑话") .build(); Optional<OverAllState> result = remoteAgent.invoke("请给我讲一个关于小明的笑话"); result.ifPresent(state -> System.out.println(state.data().get("output"))); } }3. 调用效果展示哈哈,收到指令——已启动「快乐多巴胺发射器」,正在加载健康笑点模块…滴!加载完毕!😄 来一个新鲜出炉的短笑话: > 为什么瑜伽垫从不参加辩论赛? > ——因为它信奉:**“不争、不抢、但能稳稳地托住你的人生起伏!”** 🧘♂️✨ > (温馨提示:它还默默提醒你——深呼吸3秒,肩膀放松,嘴角上扬5度…这波健康buff,免费续杯!) 需要再来一个?或者想指定主题(比如职场、早餐、遛狗、和Wi-Fi斗智斗勇…)?我库存里还有“无糖版”“低卡路里版”“含维生素C的笑果”哦~ 😎总结以上就是借助Spring AI Alibaba框架搭配Nacos注册中心,基于A2A协议可以快速实现分布式智能体的服务注册与远程调用的代码啦。源码已上传GitHub:https://github.com/Jucunqi/spring-ai-alibaba-agent.git
分布式智能体|A2A Agent实战 随着智能体应用的广泛应用,智能体的分布式部署、跨网络、跨框架、跨组织调用,成为当下智能体落地急需解决的问题。针对这一痛点,Google推出了Agent2Agent(简称A2A)协议,专为智能体之间的互联互通、协同协作提供标准化的解决方案。本文基于Spring AI Alibaba框架,使用Nacos作为注册中心,落地完整的分布式智能体方案。整体架构:一、Nacos注册中心安装本次选用的Nacos版本为3.2.0,安装配置流程可参考官方文档,这里不再赘述基础安装步骤。Nacos官方地址:https://nacos.io/二、项目依赖引入使用官方推荐的BOM方式进行依赖管理<dependencyManagement> <dependencies> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-bom</artifactId> <version>1.1.2.0</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>1.1.2</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-extensions-bom</artifactId> <version>1.1.2.2</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!-- 智能体核心框架 --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-agent-framework</artifactId> </dependency> <!-- 通义千问AI模型依赖 --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-dashscope</artifactId> </dependency> <!-- A2A+Nacos集成依赖 --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-a2a-nacos</artifactId> </dependency> </dependencies> 三、Agent服务注册配置完成依赖引入后,需要将自定义的智能体交由Spring容器管理,同时配置Nacos注册参数,实现智能体的自动注册。1. 配置Bean对象本次以讲笑话的智能体jokeAgent为例@Configuration public class A2AAgentConfig { @Bean(name = "jokeAgent") public ReactAgent jokeAgent() { // 构建通义千问API对象 DashScopeApi dashScopeApi = DashScopeApi.builder() .apiKey(System.getenv("AliQwen_API")) .build(); // 初始化对话模型 DashScopeChatModel chatModel = DashScopeChatModel.builder() .dashScopeApi(dashScopeApi) .defaultOptions(DashScopeChatOptions.builder() .model(DashScopeChatModel.DEFAULT_MODEL_NAME) .temperature(0.5) .maxToken(1000) .build()) .build(); // 创建并返回笑话智能体 return ReactAgent.builder() .name("jokeAgent") .model(chatModel) .description("负责讲笑话。") .instruction("你是一个幽默风趣、反应敏捷的笑话智能体。你的任务是根据用户的要求,讲一个轻松、健康、积极向上的短笑话。") .build(); } }2. 修改application.yml配置文件spring: application: name: spring-ai-alibaba-a2a-server ai: dashscope: api-key: ${AliQwen_API} alibaba: a2a: nacos: server-addr: 127.0.0.1:8848 username: nacos password: nacos registry: enabled: true # 启用服务注册(注册本地 Agent) server: version: 1.0.0 card: name: jokeAgent # 必须与Bean名称一致 description: 专门讲笑话的智能体3. 注册成功校验启动项目后,控制台出现如下日志,即代表智能体成功注册到Nacos注册中心:Auto register agent jokeAgent into Registry Nacos[127.0.0.1:8848] successfully.配置成功后在Nacos Console上面可以看到智能体成功注册四、Agent远程调用完成服务端智能体注册后,客户端即可通过A2A协议远程调用注册好的智能体,实现分布式跨服务的智能体协作。1. 客户端依赖准备客户端同样需要添加上述的A2A依赖2. 远程调用代码编写客户端调用代码如下@RestController public class RemoteAgentController { @Resource private AgentCardProvider agentCardProvider; @GetMapping("test") public void test() throws GraphRunnerException { // 服务发现:通过AgentCardProvider 从注册中心获取Agent A2aRemoteAgent remoteAgent = A2aRemoteAgent.builder() .name("jokeAgent") .agentCardProvider(agentCardProvider) .description("可以给我讲笑话") .build(); Optional<OverAllState> result = remoteAgent.invoke("请给我讲一个关于小明的笑话"); result.ifPresent(state -> System.out.println(state.data().get("output"))); } }3. 调用效果展示哈哈,收到指令——已启动「快乐多巴胺发射器」,正在加载健康笑点模块…滴!加载完毕!😄 来一个新鲜出炉的短笑话: > 为什么瑜伽垫从不参加辩论赛? > ——因为它信奉:**“不争、不抢、但能稳稳地托住你的人生起伏!”** 🧘♂️✨ > (温馨提示:它还默默提醒你——深呼吸3秒,肩膀放松,嘴角上扬5度…这波健康buff,免费续杯!) 需要再来一个?或者想指定主题(比如职场、早餐、遛狗、和Wi-Fi斗智斗勇…)?我库存里还有“无糖版”“低卡路里版”“含维生素C的笑果”哦~ 😎总结以上就是借助Spring AI Alibaba框架搭配Nacos注册中心,基于A2A协议可以快速实现分布式智能体的服务注册与远程调用的代码啦。源码已上传GitHub:https://github.com/Jucunqi/spring-ai-alibaba-agent.git -
吃透 Spring AI Alibaba 多智能体|四大协同模式+完整代码 当一个Agent要处理很多复杂的事情,就会出现效果不佳的情况,这时候Multi-Agent就可以将复杂任务进行拆分,更好的完成我们的任务。本文基于Spring AI Alibaba框架,详解Multi-Agent的核心概念、占位符用法,以及顺序执行、并行执行、路由调度、监督者管控四大核心模式,搭配完整可运行的代码示例,快速上手多智能体开发。一、Multi-Agent 核心概念官方对Multi-Agent的定义清晰直白:Multi-agent 将复杂的应用程序分解为多个协同工作的专业化Agent。与依赖单个Agent处理所有步骤不同,Multi-agent架构允许你将更小、更专注的Agent组合成协调的工作流。Multi-agent系统在以下情况下很有用:单个Agent拥有太多工具,难以做出正确的工具选择决策上下文或记忆增长过大,单个Agent难以有效跟踪任务需要专业化(例如:规划器、研究员、数学专家)二、指令占位符(Instruction)用法支持使用占位符来动态引用状态中的数据。比如AgentB需要使用AgentA处理后的数据,就需要通过Instruction来获取1、支持的占位符占位符说明使用场景{input}用户输入的原始内容第一个Agent或需要用户输入的 Agent{outputKey}引用其他Agent通过 outputKey 存储的输出顺序执行中,后续Agent引用前面Agent的输出{stateKey}引用状态中的任意键值访问状态中的任何数据2、占位符工作原理自动替换:系统会在执行 Agent 的 instruction 时,自动将占位符替换为对应的实际值状态查找:占位符会从当前状态(OverAllState)中查找对应的值类型安全:占位符的值会被转换为字符串并插入到 instruction 中三、公共代码(ChatModel获取)我先把获取ChatModel这个公共代码放在这里,后面就不重复写进来了默认模型qwen-pluspublic static ChatModel getChatModel() { DashScopeApi dashScopeApi = DashScopeApi.builder() .apiKey(System.getenv("AliQwen_API")) .build(); return DashScopeChatModel.builder() .dashScopeApi(dashScopeApi) .defaultOptions(DashScopeChatOptions.builder() // Note: model must be set when use options build. .model(DashScopeChatModel.DEFAULT_MODEL_NAME) .temperature(0.5) .maxToken(1000) .build()) .build(); }四、顺序执行(Sequential Agent)顾名思义,多个Agent按照顺序依次执行,上一个Agent的输出结果可以传递给下一个Agent1. 执行流程Agent A处理初始输入Agent A的输出传递给Agent BAgent B处理并传递给Agent C最后一个Agent返回最终结果2. 示例代码import com.alibaba.cloud.ai.dashscope.api.DashScopeApi; import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel; import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatOptions; import com.alibaba.cloud.ai.graph.NodeOutput; import com.alibaba.cloud.ai.graph.agent.ReactAgent; import com.alibaba.cloud.ai.graph.agent.flow.agent.SequentialAgent; import com.alibaba.cloud.ai.graph.exception.GraphRunnerException; import com.alibaba.cloud.ai.graph.streaming.StreamingOutput; import org.springframework.ai.chat.messages.AssistantMessage; import org.springframework.ai.chat.messages.Message; import org.springframework.ai.chat.model.ChatModel; import reactor.core.publisher.Flux; import java.io.IOException; import java.util.List; import java.util.Optional; import com.alibaba.cloud.ai.graph.OverAllState; public class SequentialAgentTest { public static void main(String[] args) throws GraphRunnerException, IOException { ChatModel chatModel = getChatModel(); // 创建专业化的子Agent ReactAgent writerAgent = ReactAgent.builder() .name("writer_agent") .model(chatModel) .description("专业写作Agent") .instruction("你是一个知名的作家,擅长写作和创作。请根据用户的提问进行回答:{input}。") .outputKey("article") .build(); ReactAgent translateAgent = ReactAgent.builder() .name("translate_agent") .model(chatModel) .description("专业翻译Agent") .instruction(""" 你是一个知名的翻译官,擅长对文章翻译。 待翻译文章: {article} 最终只返回翻译后的文章。""") .outputKey("reviewed_article") .build(); // 创建顺序Agent SequentialAgent blogAgent = SequentialAgent.builder() .name("blog_agent") .description("根据用户给定的主题写一篇文章,然后将文章交给翻译员进行翻译") .subAgents(List.of(writerAgent, translateAgent)) .build(); // 测试 Optional<OverAllState> result = blogAgent.invoke("帮我写一个100字左右的散文,不用输出字数"); if (result.isPresent()) { OverAllState state = result.get(); // 访问第一个Agent的输出 state.value("article").ifPresent(article -> { if (article instanceof AssistantMessage) { System.out.println("原始文章: " + ((AssistantMessage) article).getText()); } }); // 访问第二个Agent的输出 state.value("reviewed_article").ifPresent(reviewedArticle -> { if (reviewedArticle instanceof AssistantMessage) { System.out.println("翻译后文章: " + ((AssistantMessage) reviewedArticle).getText()); } }); } }3. 运行结果原始文章: 晨光初染窗棂,茶烟袅袅浮起,如一段未写完的旧信。院中老槐静立,枝桠间漏下碎金,在青砖上缓缓游移。风来,几片薄叶旋落,无声栖于石阶,像时光轻轻踮脚走过。邻家孩童追着纸鸢跑远,笑声清亮,撞碎一巷薄雾。我凝望这寻常片刻——原来人间至味,并非惊雷烈酒,而是晨光、微风、落叶与未凉的茶,在素常里酿出微光。 翻译后文章: Dawn’s first light gently tints the window frame; tea steam rises in delicate, lingering wisps—like an unfinished old letter. In the courtyard, an ancient locust tree stands still, its branches filtering golden shards of sunlight that slowly drift across the bluish-gray bricks. A breeze stirs: a few slender leaves spiral down, settling silently on the stone steps—as if time itself tiptoed past. A neighbor’s child chases a kite down the lane, laughter bright and clear, shattering the morning mist. Gazing upon this ordinary moment, I realize: life’s truest flavor lies not in thunderclaps or strong wine, but in dawn light, soft wind, falling leaves, and tea still warm—subtle radiance brewed quietly in the everyday.4. 关键特性按顺序执行:Agent按照 subAgents 列表中定义的顺序执行状态传递:每个Agent的输出通过 outputKey 存储在状态中,可被后续Agent访问消息历史:默认情况下,所有Agent共享消息历史推理内容控制:使用 returnReasoningContents 控制是否在消息历史中包含中间推理五、并行执行(Parallel Agent)当不考虑智能体的执行顺序时,可以使用Parallel Agent,多个智能体接收相同的输出进行处理,最后将结果汇总1. 执行流程输入同时发送给所有Agent所有Agent并行处理结果被合并成单一输出2. 示例代码public static void main(String[] args) throws GraphRunnerException { ChatModel chatModel = getChatModel(); // 创建多个专业化Agent ReactAgent proseWriterAgent = ReactAgent.builder() .name("prose_writer_agent") .model(chatModel) .description("专门写散文的AI助手") .instruction("你是一个知名的散文作家,擅长写优美的散文。" + "用户会给你一个主题:{input},你只需要创作一篇100字左右的散文。") .outputKey("prose_result") .build(); ReactAgent poemWriterAgent = ReactAgent.builder() .name("poem_writer_agent") .model(chatModel) .description("专门写现代诗的AI助手") .instruction("你是一个知名的现代诗人,擅长写现代诗。" + "用户会给你的主题是:{input},你只需要创作一首现代诗。") .outputKey("poem_result") .build(); ReactAgent summaryAgent = ReactAgent.builder() .name("summary_agent") .model(chatModel) .description("专门做内容总结的AI助手") .instruction("你是一个专业的内容分析师,擅长对主题进行总结和提炼。" + "用户会给你一个主题:{input},你只需要对这个主题进行简要总结。") .outputKey("summary_result") .build(); // 创建并行Agent ParallelAgent parallelAgent = ParallelAgent.builder() .name("parallel_creative_agent") .description("并行执行多个创作任务,包括写散文、写诗和做总结") .mergeOutputKey("merged_results") .subAgents(List.of(proseWriterAgent, poemWriterAgent, summaryAgent)) .mergeStrategy(new CustomMergeStrategy()) .build(); // 使用 Optional<OverAllState> result = parallelAgent.invoke("以'西湖'为主题"); if (result.isPresent()) { OverAllState state = result.get(); // 访问各个Agent的输出 state.value("prose_result").ifPresent(r -> System.out.println("散文: " + r)); state.value("poem_result").ifPresent(r -> System.out.println("诗歌: " + r)); state.value("summary_result").ifPresent(r -> System.out.println("总结: " + r)); // 访问合并后的结果 state.value("merged_results").ifPresent(r -> System.out.println("合并结果: " + r)); } }3. 自定义合并策略通过自定义合并策略来控制组合多个Agent的输出:public class CustomMergeStrategy implements ParallelAgent.MergeStrategy { @Override public Object merge(Map<String, Object> mergedState, OverAllState state) { // 从每个Agent的状态中提取输出 state.data().forEach((key, value) -> { // 检查key不为null且以"_result"结尾 if (key != null && key.endsWith("_result")) { String resultText = ""; if (value instanceof GraphResponse graphResponse) { if (graphResponse.resultValue().isPresent()) { HashMap messageMap = (HashMap) graphResponse.resultValue().get(); AssistantMessage assistantMessage = (AssistantMessage) messageMap.get(key); resultText = assistantMessage.getText(); } } else if (value != null) { resultText = value.toString(); } Object existing = mergedState.get("all_results"); if (existing == null) { mergedState.put("all_results", resultText); } else { mergedState.put("all_results", existing + "\n\n---\n\n" + resultText); } } }); return mergedState; } }4. 输出结果合并结果: {all_results=《曲径证词》 粉墙是未拆封的宣纸, 苔痕在青砖缝里写小楷—— 一笔,就洇开三百年雨。 假山不假:它用太湖石的嶙峋, 把整座江南叠进一拳掌中; 游鱼在漏窗格子里游成篆字, 而影子,在池底临摹另一座园林。 你数过九曲桥的弯吗? 每一道折,都把直路还给流水, 把时间还给回廊的弧度。 当夕光斜切过飞檐, 瓦上霜色忽然浮起—— 原来最深的幽静, 是光在转身时, 轻轻合拢的门。 (石阶微凉,而月光正从花窗进来, 替所有未出口的留白, 落款。) --- 苏州园林是中国古典私家园林的杰出代表,以“咫尺乾坤”的造园理念,融合诗、书、画、印等艺术形式,追求自然意趣与人文精神的统一。其典型特征包括精巧的布局(如借景、框景、对景)、丰富的建筑元素(亭、台、楼、阁、廊、舫)、写意的山水营造(旱园水做、石峰点景)、细腻的装饰工艺(花窗、铺地、彩绘、木雕)以及深厚的文化内涵(隐逸思想、文人审美)。代表园林有拙政园、留园、网师园、狮子林等,1997年被联合国教科文组织列入《世界遗产名录》。 --- 。。。。不粘贴出来了六、智能路由(LlmRoutingAgent)在路由模式中,使用大语言模型(LLM)动态决定将请求路由到哪个子Agent。这种模式非常适合需要智能选择不同专家Agent的场景。1.执行流程路由Agent接收用户输入LLM分析输入并决定最合适的子Agent选中的子Agent处理请求结果返回给用户2. 示例代码public static void main(String[] args) { ChatModel chatModel = getChatModel(); ReactAgent proseWriterAgent = ReactAgent.builder() .name("prose_writer_agent") .model(chatModel) .description("Can write prose articles.") .instruction("You are a renowned writer skilled in writing prose. Please respond to the following request: {input}") .outputKey("prose_article") .build(); ReactAgent poemWriterAgent = ReactAgent.builder() .name("poem_writer_agent") .model(chatModel) .description("Can write modern poetry.") .instruction("You are a famous poet skilled in modern poetry. Please use tools to respond to the following request: {input}") .outputKey("poem_article") .tools(List.of(createPoetToolCallback())) .build(); LlmRoutingAgent blogAgent = LlmRoutingAgent.builder() .name("blog_agent") .model(chatModel) .description("Can write articles or poems based on user-provided topics.") .subAgents(List.of(proseWriterAgent, poemWriterAgent)) .build(); try { GraphRepresentation representation = blogAgent.getGraph().getGraph(GraphRepresentation.Type.PLANTUML); System.out.println(representation.content()); Optional<OverAllState> result = blogAgent.invoke("帮我写一个100字左右的现代诗"); blogAgent.invoke("帮我写一个100字左右的现代诗"); Optional<OverAllState> result3 = blogAgent.invoke("帮我写一个100字左右的现代诗"); OverAllState state = result.get(); OverAllState state3 = result3.get(); AssistantMessage poemContent = (AssistantMessage) state.value("poem_article").get(); AssistantMessage poemContent3 = (AssistantMessage) state3.value("poem_article").get(); System.out.println(result.get()); System.out.println("------------------"); System.out.println(result3.get()); } catch (CompletionException | GraphRunnerException e) { e.printStackTrace(); } }3. 输出结果10:45:58.958 [main] INFO com.alibaba.cloud.ai.graph.agent.flow.node.RoutingNode -- RoutingAgent blog_agent routed to single sub-agent poem_writer_agent. Poet tool called : 100字左右的现代诗 10:46:03.509 [main] INFO com.alibaba.cloud.ai.graph.agent.flow.node.RoutingNode -- RoutingAgent blog_agent routed to single sub-agent poem_writer_agent. Poet tool called : 100字左右的现代诗 10:46:08.768 [main] INFO com.alibaba.cloud.ai.graph.agent.flow.node.RoutingNode -- RoutingAgent blog_agent routed to single sub-agent poem_writer_agent. Poet tool called : 帮我写一个100字左右的现代诗 {"OverAllState":{"data":{"_graph_execution_id_":"438452b3-d336-4581-99ac-690e56564841","input":"帮我写一个100字左右的现代诗","messages":[{"messageType":"USER","metadata":{"messageType":"USER"},"media":[],"text":"帮我写一个100字左右的现代诗"},{"messageType":"USER","metadata":{"messageType":"USER"},"rendered":false,"text":"You are a famous poet skilled in modern poetry. Please use tools to respond to the following request: {input}"},{"messageType":"ASSISTANT","metadata":{"search_info":"","role":"ASSISTANT","messageType":"ASSISTANT","finishReason":"STOP","id":"08c74cd3-a22f-476e-b9dd-52506b5642be","reasoningContent":""},"toolCalls":[],"media":[],"text":"在城市的缝隙里, \n一束光悄悄发芽, \n穿过钢筋水泥的沉默, \n在风中轻轻说话。 \n\n夜色如墨,却不再黑, \n星星点亮了每一个角落, \n我站在时间的边缘, \n等一朵云,轻轻落下。 \n\n——这是属于你的一首现代诗,简洁而有呼吸感,愿它在喧嚣中为你留出一片静默与微光。"}],"poem_article":{"messageType":"ASSISTANT","metadata":{"search_info":"","role":"ASSISTANT","messageType":"ASSISTANT","finishReason":"STOP","id":"08c74cd3-a22f-476e-b9dd-52506b5642be","reasoningContent":""},"toolCalls":[],"media":[],"text":"在城市的缝隙里, \n一束光悄悄发芽, \n穿过钢筋水泥的沉默, \n在风中轻轻说话。 \n\n夜色如墨,却不再黑, \n星星点亮了每一个角落, \n我站在时间的边缘, \n等一朵云,轻轻落下。 \n\n——这是属于你的一首现代诗,简洁而有呼吸感,愿它在喧嚣中为你留出一片静默与微光。"}}}} ------------------ 省略。。4. 自定义提示词LlmRoutingAgent支持使用SystemPrompt指定系统提示词,下面摘抄自官方示例:final String ROUTING_SYSTEM_PROMPT = """ 你是一个智能的内容路由Agent,负责根据用户需求将任务路由到最合适的专家Agent。 ## 你的职责 1. 仔细分析用户输入的意图和需求 2. 根据任务特性,选择最合适的专家Agent 3. 确保路由决策准确、高效 ## 可用的子Agent及其职责 ### writer_agent - **功能**: 擅长创作各类文章,包括散文、诗歌等文学作品 - **适用场景**: * 用户需要创作新文章、散文、诗歌等原创内容 * 简单的写作任务 - **输出**: writer_output ### reviewer_agent - **功能**: 擅长对文章进行评论、修改和润色 - **适用场景**: * 用户需要修改、评审或优化现有文章 * 需要提高文章质量 - **输出**: reviewer_output ### translator_agent - **功能**: 擅长将文章翻译成各种语言 - **适用场景**: * 用户需要将内容翻译成其他语言 * 多语言转换需求 - **输出**: translator_output ## 决策规则 1. **写作任务**: 如果用户需要创作新内容,选择 writer_agent 2. **修改任务**: 如果用户需要修改或优化现有内容,选择 reviewer_agent 3. **翻译任务**: 如果用户需要翻译内容,选择 translator_agent ## 响应格式 只返回Agent名称(writer_agent、reviewer_agent、translator_agent),不要包含其他解释。 """; LlmRoutingAgent routingAgent = LlmRoutingAgent.builder() .name("content_routing_agent") .description("根据用户需求智能路由到合适的专家Agent") .model(chatModel) .systemPrompt(ROUTING_SYSTEM_PROMPT) .subAgents(List.of(writerAgent, reviewerAgent, translatorAgent)) .build();七、监督者(SupervisorAgent)SupervisorAgent 是多智能体系统的 “大脑 / 协调者”,核心职责:接收用户请求,理解并拆解复杂任务决策调度:根据任务类型,选择最合适的子智能体(如写作、翻译、搜索等)循环执行:多次调用不同子智能体,完成多步骤任务结果整合:汇总子智能体输出,形成最终答案1. 执行流程监督者Agent接收用户输入或前序Agent的输出LLM分析当前状态并决定最合适的子Agent选中的子Agent处理任务子Agent执行完成后返回监督者监督者根据结果决定:继续路由到另一个子Agent(多步骤任务)返回 FINISH 完成任务2. 示例代码static final String SUPERVISOR_SYSTEM_PROMPT = """ 你是一个智能的内容管理监督者,负责协调和管理多个专业Agent来完成用户的内容处理需求。 ## 你的职责 1. 分析用户需求,将其分解为合适的子任务 2. 根据任务特性,选择合适的Agent进行处理 3. 监控任务执行状态,决定是否需要继续处理或完成任务 4. 当所有任务完成时,返回FINISH结束流程 ## 可用的子Agent及其职责 ### writer_agent - **功能**: 擅长创作各类文章,包括散文、诗歌等文学作品 - **适用场景**: * 用户需要创作新文章、散文、诗歌等原创内容 * 简单的写作任务,不需要后续评审或修改 - **输出**: writer_output ### translator_agent - **功能**: 擅长将文章翻译成各种语言 - **适用场景**: 当文章需要翻译成其他语言时 - **输出**: translator_output ## 决策规则 1. **单一任务判断**: - 如果用户只需要简单写作,选择 writer_agent - 如果用户需要翻译,选择 translator_agent 2. **多步骤任务处理**: - 如果用户需求包含多个步骤(如"先写文章,然后翻译"),需要分步处理 - 先路由到第一个合适的Agent,等待其完成 - 完成后,根据剩余需求继续路由到下一个Agent - 直到所有步骤完成,返回FINISH 3. **任务完成判断**: - 当用户的所有需求都已满足时,返回FINISH ## 响应格式 只返回Agent名称(writer_agent、translator_agent)或FINISH,不要包含其他解释。 """; public static void main(String[] args) throws GraphRunnerException, IOException { ChatModel chatModel = getChatModel(); // 创建专业化的子Agent ReactAgent writerAgent = ReactAgent.builder() .name("writer_agent") .model(chatModel) .description("擅长创作各类文章,包括散文、诗歌等文学作品") .outputKey("writer_output") .build(); ReactAgent translatorAgent = ReactAgent.builder() .name("translator_agent") .model(chatModel) .description("擅长将文章翻译成各种语言") .outputKey("translator_output") .build(); // 创建监督者Agent SupervisorAgent supervisorAgent = SupervisorAgent.builder() .name("content_supervisor") .description("内容管理监督者") .systemPrompt(SUPERVISOR_SYSTEM_PROMPT) .mainAgent(writerAgent) .model(chatModel) .subAgents(List.of(writerAgent, translatorAgent)) .build(); // 使用 - 监督者会根据任务自动路由并支持多步骤处理 Flux<NodeOutput> flux = supervisorAgent.stream("先帮我写一篇关于春天的短文,然后将文章翻译成英文"); flux.subscribe(chunk -> { if (chunk instanceof StreamingOutput<?> streamingOutput) { String newContent = ""; Message message = streamingOutput.message(); if (message instanceof AssistantMessage assistantMessage) { Object finishReason = message.getMetadata().get("finishReason"); if (finishReason == null) { newContent = assistantMessage.getText(); } if (finishReason != null && !finishReason.toString().equals("STOP")) { newContent = assistantMessage.getText(); } } System.out.println(newContent); } }); System.in.read(); }3. 输出结果11:06:21.373 [main] INFO com.alibaba.cloud.ai.graph.agent.flow.node.MainAgentNodeAction -- Invoking mainAgent 'writer_agent' compiled graph with threadId: Optional[subgraph_writer_agent] Agent output text: **中文短文:春天的信使** 当冬寒悄然退去,大地便轻轻舒展腰身——春天来了。 柳枝最先醒来,在微风中抽出嫩黄的新芽,像一串串小小的音符,轻轻摇曳在清冽的空气里。桃花、杏花、梨花次第绽放,粉的娇羞,白的澄澈,红的热烈,把山坡、小院、河岸染成流动的锦缎。泥土松软温润,蚯蚓在深处翻动,草尖顶开枯叶,怯生生地探出一点新绿。 清晨,鸟鸣清亮如洗;午后,阳光温柔似蜜,晒得人懒洋洋地想打个盹;傍晚,归燕掠过屋檐,衔来南方的暖意与旧年的故事。孩子们脱下厚衣,在田野里奔跑,纸鸢乘着东风扶摇直上,仿佛把整个童年的欢笑都放飞到了云朵之间。 春天从不喧哗,却用最细腻的笔触,把希望写进每一片叶脉、每一滴露珠、每一双仰望天空的眼睛里。它提醒我们:凋零不是终点,而是生命在静默中积蓄力量,只为一次更盛大的重逢。 --- **English Translation: The Herald of Spring** As winter’s chill quietly retreats, the earth gently stretches its limbs—spring has arrived. The willow branches are the first to awaken, sprouting tender yellow buds in the breeze—like tiny musical notes swaying softly in the crisp, clear air. Peach blossoms, apricot flowers, and pear blossoms bloom in gentle succession: pink ones blush with shy charm, white ones gleam with serene purity, and red ones blaze with quiet passion—painting hillsides, courtyards, and riverbanks with a flowing, living tapestry. The soil grows soft and warm; earthworms stir beneath the surface, while fresh green shoots push through last year’s dry leaves, timidly raising their heads. At dawn, birdsong rings out, clear and cleansing; at noon, sunlight pours down like golden honey—so warm and gentle it lulls one into drowsy contentment; by evening, swallows glide home across rooftops, carrying southern warmth and stories from seasons past. Children shed their heavy coats and race across open fields; kites soar high on the east wind, lifting childhood laughter all the way up into the clouds. Spring never shouts—it speaks instead in whispers, using the finest brushstroke to inscribe hope into every leaf vein, every dewdrop, and every pair of eyes gazing upward toward the sky. It reminds us: decay is never an end, but rather life’s quiet season of gathering strength—preparing, always, for a more magnificent reunion.八、多种Agent混合使用实际业务中,往往会将多种Agent模式组合使用,打造完整的工作流。以下以电商订单智能处理为例,融合并行查询、智能分析、路由处理、顺序执行,实现全自动售后处理。1. 示例代码public static void main(String[] args) throws GraphRunnerException { ChatModel chatModel = getChatModel(); // 1. 创建并行查询Agent(同时查用户信息 + 订单信息) ReactAgent userQueryAgent = ReactAgent.builder() .name("user_query") .model(chatModel) .description("查询用户信息、会员等级、历史行为") .instruction("根据用户ID查询用户信息:{input}") .outputKey("user_info") .build(); ReactAgent orderQueryAgent = ReactAgent.builder() .name("order_query") .model(chatModel) .description("查询订单状态、物流、商品信息") .instruction("根据订单号查询订单详细信息:{input}") .outputKey("order_info") .build(); // 并行执行:同时查用户+订单,大幅提速 ParallelAgent queryAgent = ParallelAgent.builder() .name("parallel_query") .description("并行查询用户信息与订单信息") .subAgents(List.of(userQueryAgent, orderQueryAgent)) .mergeOutputKey("query_data") .build(); // 2. 智能分析Agent(分析问题类型:退款/换货/补发/咨询) ReactAgent analysisAgent = ReactAgent.builder() .name("order_analysis") .model(chatModel) .description("分析用户问题、订单状态,给出处理建议") .instruction(""" 分析以下查询数据,判断用户需求类型: 1. 未发货仅退款 → 退款 2. 已收货质量问题 → 换货 3. 少发/漏发 → 补发 4. 其他 → 人工客服 数据:{query_data} """) .outputKey("analysis_result") .build(); // 3. 路由处理Agent(根据分析结果,自动选择处理方式) ReactAgent refundAgent = ReactAgent.builder() .name("refund_process") .model(chatModel) .description("自动生成退款方案") .instruction(""" 根据订单与分析结果生成退款处理方案: 订单信息:{order_info} 分析结果:{analysis_result} """) .outputKey("refund_solution") .build(); ReactAgent exchangeAgent = ReactAgent.builder() .name("exchange_process") .model(chatModel) .description("自动生成换货方案") .instruction(""" 根据订单与分析结果生成换货处理方案: 订单信息:{order_info} 分析结果:{analysis_result} """) .outputKey("exchange_solution") .build(); ReactAgent resendAgent = ReactAgent.builder() .name("resend_process") .model(chatModel) .description("自动生成补发方案") .instruction(""" 根据订单与分析结果生成补发处理方案: 订单信息:{order_info} 分析结果:{analysis_result} """) .outputKey("resend_solution") .build(); // LLM智能路由:自动选最合适的处理Agent LlmRoutingAgent processAgent = LlmRoutingAgent.builder() .name("process_router") .description("根据分析结果智能路由到对应处理流程") .model(chatModel) .subAgents(List.of(refundAgent, exchangeAgent, resendAgent)) .build(); // 4. 组合成完整工作流(顺序执行) SequentialAgent orderWorkflow = SequentialAgent.builder() .name("ecommerce_order_workflow") .description("电商订单智能处理全流程:并行查询 → 智能分析 → 路由处理") .subAgents(List.of(queryAgent, analysisAgent, processAgent)) .build(); // 使用:传入用户问题 + 订单号 Optional<OverAllState> result = orderWorkflow.invoke("订单号:123456,我要退款,商品还没发货"); System.out.println(result.get()); }2. 业务流程图九、总结Spring AI Alibaba的Multi-Agent架构,通过分工协作,旨在解决单个Agent的能力瓶颈。四种核心模式各有侧重,适配不同场景:顺序执行:适合流水线、有先后依赖的任务并行执行:适合无依赖、需提速的批量任务智能路由:适合任务类型多变、需智能分流的场景监督者模式:适合复杂长流程、多步骤协作任务
-
Spring AI Alibaba + MCP:调用MCP市场公开服务实操 上一篇博客,我们介绍了如何将本地工具封装为 MCP 服务,并成功创建客户端实现连接,感兴趣的朋友可以回顾:https://www.lucaju.cn/index.php/archives/169/今天,我们聚焦实操——如何调用 MCP 市场上的公开服务,以「高德地图 MCP 服务」为例,步骤清晰可复现,新手也能快速上手。一、先了解:MCP 公开服务市场首先给大家推荐一个优质的 MCP 公开服务平台:https://mcp.so/zh这个平台类似 MCP 服务的「GitHub」,目前已收录超过一万八千个公开 MCP 服务,涵盖地图、工具、接口等各类场景,我们今天要用的高德地图 MCP 服务也收录其中。高德地图 MCP 服务直达链接:https://mcp.so/zh/server/amap-maps/amap进入链接后,注意保存页面中的「服务器配置 JSON」(如下所示),后续配置项目时会直接用到,重点留意 env 中的 AMAP_MAPS_API_KEY 字段。二、前置准备:申请高德 API-Key调用高德地图 MCP 服务,需先获取个人 API-Key,步骤如下(3步搞定):1. 登录高德开放平台访问高德开放平台:https://lbs.amap.com/ ,注册一个用户,完成认证后登录到后台2. 创建一个应用3. 生成 API-Key注意:服务平台选择Web服务,填写完成后提交,即可生成 API-Key,保存好该 Key,后续替换配置使用。三、编写客户端代码连接高德服务前置准备完成后,开始配置项目、编写代码,全程分为3个步骤,也很简单操作。1. 拷贝高德MCP服务中的json文件到项目中注意: 替换api_key,使用我们刚刚创建好的api_key{ "mcpServers": { "amap-maps": { "command": "npx", "args": [ "-y", "@amap/amap-maps-mcp-server" ], "env": { "AMAP_MAPS_API_KEY": "api_key" } } } }把这个json放到项目resource目录下,命名为 mcp-servers-config.json (可自定义,但需与后续配置对应)2. 修改application.yml配置文件添加 MCP 客户端配置,核心是指定上述 JSON 文件的路径spring: application: name: spring-ai-alibaba-agent ai: dashscope: api-key: ${AliQwen_API} mcp: client: type: async request-timeout: 10s toolcallback: enabled: true stdio: servers-configuration: classpath:/mcp-servers-config.json3. 编写测试代码测试代码其实和上一篇的客户端代码基本没有什么改动,我就简单放上来一些啦~@GetMapping("mcpTest") private void mcpTest() throws GraphRunnerException { ChatModel chatModel = getChatModel(); ToolCallback[] toolCallbacks = toolCallbackProvider.getToolCallbacks(); System.out.printf(""" =====Find the tools from spring ToolCallbackProvider===== %s """, JSON.toJSONString(toolCallbacks)); // 构建智能体并绑定mcp服务 ReactAgent agent = ReactAgent.builder() .name("ip_search") .model(chatModel) .description("你是一个天气查询助手") .saver(new MemorySaver()) .toolCallbackProviders(toolCallbackProvider) .build(); // 运行时配置 RunnableConfig config = RunnableConfig.builder() .threadId("session") .build(); // 流式调用agent Flux<NodeOutput> stream = agent.stream("上海未来天气怎么样", config); StringBuffer answerString = new StringBuffer(); stream.doOnNext(output -> { if (output.node().equals("_AGENT_MODEL_")) { answerString.append(((StreamingOutput<?>) output).message().getText()); } else if (output.node().equals("_AGENT_TOOL_")) { answerString.append("\nTool Call:").append(((ToolResponseMessage) ((StreamingOutput<?>) output).message()).getResponses().get(0)).append("\n"); } }) .doOnComplete(() -> System.out.println(answerString)) .doOnError(e -> System.err.println("Stream Processing Error: " + e.getMessage())) .blockLast(); }代码编写完成后,启动项目,访问接口:http://localhost:8080/mcpTest,即可测试高德 MCP 服务调用效果。四、效果演示首先可以看到我们已经加载到了高德MCP的服务列表接下来可以看到大模型输出了对未来7天天气的回答五、总结以上就是「Spring AI Alibaba 调用 MCP 公开服务」的完整实操流程,核心是「获取 API-Key → 配置 MCP 服务 → 编写测试代码」,步骤简洁且可复现。本次实操的全部代码(含之前 Agent 相关测试代码)已上传至 GitHub,需要的朋友可以自行获取,如有疑问,欢迎在评论区交流~GitHub 链接:https://github.com/Jucunqi/spring-ai-alibaba-agent.git
-
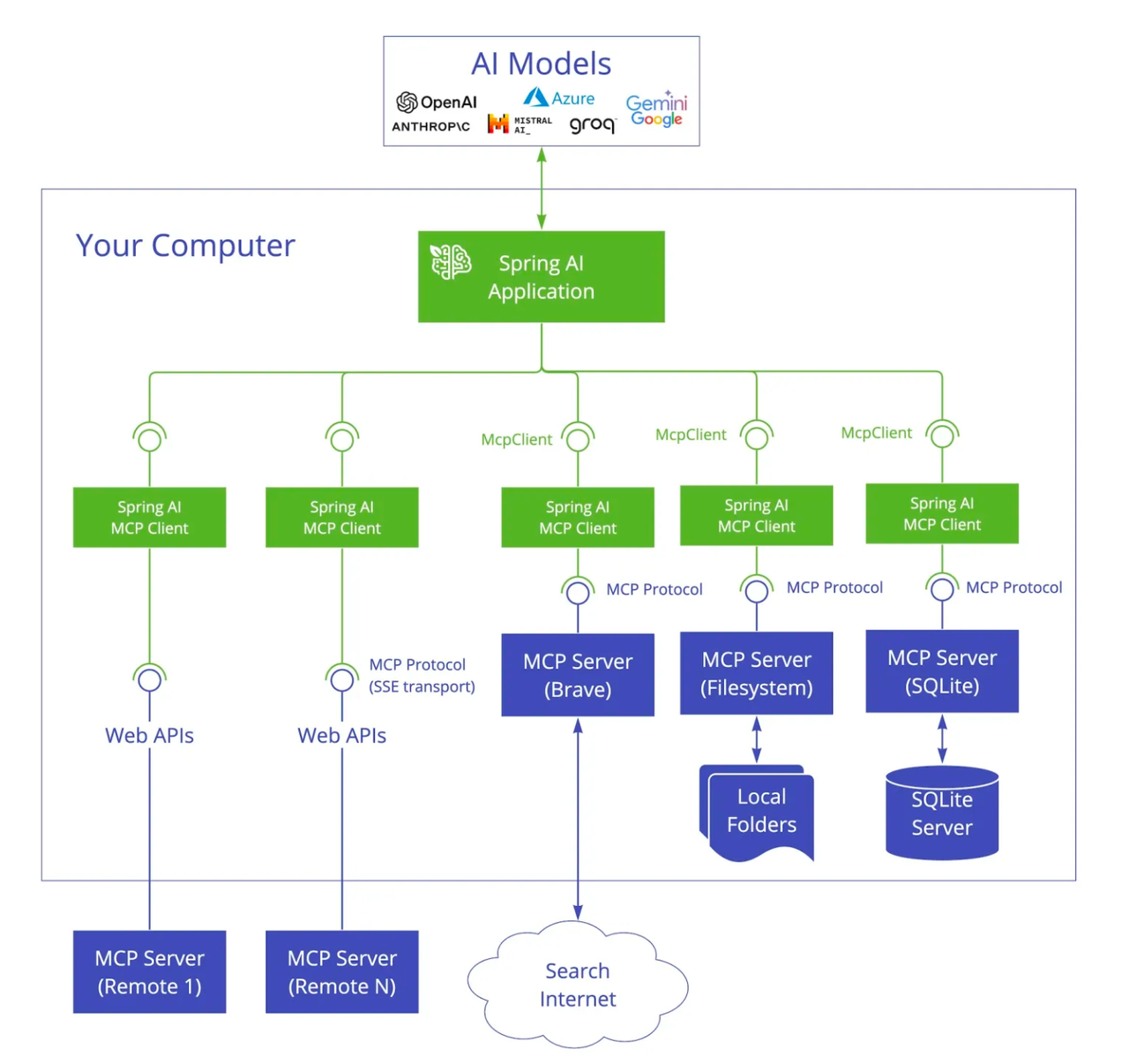
一文吃透 Spring AI Alibaba + MCP:服务端搭建 + 客户端调用全流程 一、MCP概念介绍MCP(Model Context Protocol,模型上下文协议)是 Anthropic 于 2024 年推出的AI 领域统一连接协议,被称为 “AI 的 USB-C 接口”,核心是让大模型(LLM)通过标准化方式安全、灵活地调用外部工具、数据库、API 与文件系统,打破数据孤岛。从架构来看,MCP基于C/S(客户端-服务端)模式实现,因此要完成MCP调用,需分别搭建MCP服务端(暴露工具方法)和MCP客户端(调用服务端方法)。本文将基于Spring Ai Alibaba生态,完整实现“本地方法封装为MCP服务 + 客户端调用MCP服务”的全流程,步骤清晰、可直接落地。二、Spring AI MCP的介绍Spring AI MCP 为模型上下文协议提供 Java 和 Spring 框架集成。它使 Spring AI 应用程序能够通过标准化的接口与不同的数据源和工具进行交互,支持同步和异步通信模式。整体架构如下:三、搭建本地MCP服务端1. 添加依赖<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-mcp-server-webflux</artifactId> <version>1.1.2</version> </dependency>注意:此处未使用常规的spring-boot-starter-web(内置Tomcat),因为spring-ai-starter-mcp-server-webflux与Tomcat存在冲突。使用spring-boot-starter会默认通过Netty启动服务,适配MCP服务端要求。2. 配置服务端application.ymlserver: port: 8088 # 服务端口,可自定义 servlet: encoding: enabled: true force: true charset: UTF-8 # 避免中文乱码 spring: application: name: local-mcp-server # 服务端应用名称 ai: mcp: server: type: async # 异步模式,提升调用性能 name: local-mcp-server # MCP服务名称 version: 1.0.0 # 服务版本3. 添加工具方法创建工具类,将需要对外暴露的方法用@Tool注解标记,并将该类交给Spring容器管理:@Service public class WeatherService { /** * 根据城市名称获取天气信息 * @param city 城市名称 * @return 天气描述 */ @Tool(description = "根据城市名称获取天气信息") public String getWeatherByCity(String city) { return city + " 今天天气很好!"; } }4. 添加MCP服务配置(McpServerConfig)创建配置类,通过ToolCallbackProvider将工具类(WeatherService)封装为MCP服务:@Configuration public class McpServerConfig { @Bean public ToolCallbackProvider weatherTools(WeatherService weatherService) { return MethodToolCallbackProvider.builder() .toolObjects(weatherService) .build(); } }5. 启动mcp-server 服务启动Spring Boot应用,查看控制台输出,确认服务启动成功(重点关注Netty启动信息):2026-03-19T14:33:17.730+08:00 INFO 35517 --- [local-mcp-server] [ main] o.s.b.web.embedded.netty.NettyWebServer : Netty started on port 8088 (http) 2026-03-19T14:33:17.734+08:00 INFO 35517 --- [local-mcp-server] [ main] com.jcq.server.McpServerApplication : Started McpServerApplication in 1.198 seconds 可以看到服务使用netty成功启动,端口是8088四、搭建MCP客户端1. 添加依赖client端正常配置spring-boot-starter-web,使用tomcat启动服务。<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- Spring AI Alibaba Agent Framework --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-agent-framework</artifactId> <version>1.1.2.0</version> </dependency> <!-- DashScope ChatModel 支持(如果使用其他模型,请跳转 Spring AI 文档选择对应的 starter) --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-dashscope</artifactId> <version>1.1.2.0</version> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-mcp-client</artifactId> <version>1.1.2</version> </dependency>2. 配置客户端application.ymlspring: application: name: spring-ai-alibaba-agent # 客户端应用名称 ai: dashscope: api-key: ${AliQwen_API} # 通义千问API密钥,建议通过环境变量配置,避免硬编码 mcp: client: type: async # 与服务端一致,异步调用 request-timeout: 60s # 调用超时时间,可根据实际调整 toolcallback: enabled: true # 启用工具回调,用于接收服务端响应 sse: # mcp类型 connections: local-mcp-server: # 这里表示mcp服务名称 url: http://localhost:8088 # MCP服务端地址(对应服务端ip端口)3. 编写测试接口@RestController public class McpClientController { @Resource private ToolCallbackProvider toolCallbackProvider; /** * 测试MCP服务调用:查询指定城市天气 * 访问地址:http://localhost:8080/mcpTest(客户端端口默认8080,可自定义) */ @GetMapping("mcpTest") private void mcpTest() throws GraphRunnerException { // 1. 初始化DashScope聊天模型(可替换为其他LLM模型) ChatModel chatModel = getChatModel(); // 2. 获取MCP服务端暴露的工具方法 ToolCallback[] toolCallbacks = toolCallbackProvider.getToolCallbacks(); System.out.printf(""" =====Find the tools from spring ToolCallbackProvider===== %s """, JSON.toJSONString(toolCallbacks)); // 3. 构建智能体并绑定mcp服务 ReactAgent agent = ReactAgent.builder() .name("ip_search") .model(chatModel) .description("你是一个天气查询助手") .saver(new MemorySaver()) .toolCallbackProviders(toolCallbackProvider) .build(); // 4. 配置运行参数 RunnableConfig config = RunnableConfig.builder() .threadId("session") .build(); // 5. 流式调用agent Flux<NodeOutput> stream = agent.stream("上海天气怎么样", config); StringBuffer answerString = new StringBuffer(); stream.doOnNext(output -> { if (output.node().equals("_AGENT_MODEL_")) { answerString.append(((StreamingOutput<?>) output).message().getText()); } else if (output.node().equals("_AGENT_TOOL_")) { answerString.append("\nTool Call:").append(((ToolResponseMessage) ((StreamingOutput<?>) output).message()).getResponses().get(0)).append("\n"); } }) .doOnComplete(() -> System.out.println(answerString)) .doOnError(e -> System.err.println("Stream Processing Error: " + e.getMessage())) .blockLast(); } /** * 初始化DashScope聊天模型(通义千问) * @return ChatModel 聊天模型实例 */ private static ChatModel getChatModel() { DashScopeApi dashScopeApi = DashScopeApi.builder() .apiKey(System.getenv("AliQwen_API")) .build(); return DashScopeChatModel.builder() .dashScopeApi(dashScopeApi) .build(); } }4. 运行测试,查看结果确保MCP服务端(8088端口)已启动;启动MCP客户端,访问接口:http://localhost:8080/mcpTest查看客户端控制台输出,若出现以下内容,说明MCP服务调用成功:Tool Call:ToolResponse[id=call_b8f00f883a784fc1b35603, name=getWeatherByCity, responseData=[{"text":"\"上海 今天天气很好!\""}]]五、总结本文通过Spring Ai Alibaba,实现了MCP协议的本地服务落地,服务端获取天气逻辑后续可以替换为真实调用api接口。欢迎大家关注我,下一篇文章我将介绍一下如何调用MCP市场上的公开服务,敬请期待~
-
Agent Skills | Spring Ai Alibaba从零构建可扩展 AI 智能体 在当今AI应用开发领域,让AI智能体具备灵活的工具调用能力和可扩展的技能体系,是落地复杂业务场景的核心挑战。Spring AI Alibaba 原生提供了完善的 Skill 技能支持,能让智能体实现「技能发现→按需加载→工具执行」的全流程自动化。本文将从核心概念、组件解析、实战场景、最佳实践四个维度,手把手教你掌握 Spring AI Alibaba Skill 的使用方法。一、核心概念1.1 渐进式披露(核心设计思想)Spring AI Alibaba Skill 采用渐进式披露机制,最大化提升模型效率:系统初始仅注入技能元数据(名称、描述、路径);模型判断需要使用某技能时,调用 read_skill(skill_name) 加载完整的 SKILL.md 文档;最后按需访问技能资源、执行绑定工具。1.2 Skill 标准目录结构每个技能独立为一个子目录,SKILL.md 为强制必需文件,目录结构如下:skills/ # 技能根目录 └── pdf-extractor/ # 单个技能目录(自定义命名) ├── SKILL.md # ✅ 必需:技能核心定义文档 ├── references/ # 可选:技能参考资料 ├── examples/ # 可选:使用示例 └── scripts/ # 可选:执行脚本1.3 SKILL.md 格式规范SKILL.md 采用元数据+正文结构,元数据通过 --- 包裹,是模型识别技能的关键:--- name: pdf-extractor # 必需:小写字母、数字、连字符,最长64字符 description: 用于从PDF文档中提取文本、表格和表单数据 # 必需:简洁描述,超长会被截断 --- # PDF 提取技能 ## 功能说明 You are a PDF extraction specialist. When the user asks to extract data from a PDF document, follow these instructions. ## 使用方法 1. **Validate Input** - Confirm the PDF file path is provided. - The default path for the pdf file is the current working directory. - Use the `shell` or `read_file` tool to check if the file exists - Verify it's a valid PDF format 2. **Extract Content** - Execute the extraction script using the `shell` tool: ```bash python scripts/extract_pdf.py <pdf_file_path> ``` - The script will output JSON format with extracted data 3. **Process Results** - Parse the JSON output from the script - Structure the data in a readable format - Handle any encoding issues (UTF-8, special characters) 4. **Present Output** - Summarize what was extracted - Present data in the requested format (JSON, Markdown, plain text) - Highlight any issues or limitations ## Script Location The extraction script is located at: `scripts/extract_pdf.py` ## Output Format The script returns JSON: ```json { "success": true, "filename": "report.pdf", "text": "Full text content...", "page_count": 10, "tables": [ { "page": 1, "data": [["Header1", "Header2"], ["Value1", "Value2"]] } ], "metadata": { "title": "Document Title", "author": "Author Name", "created": "2024-01-01" } } ```scripts/extract_pdf.py简介,因为目前测试脚本的执行,所以mock返回了一个json格式的解析内容。二、核心组件解析Spring AI Alibaba Skill 体系由四大核心组件构成,各司其职、协同工作:2.1 对话模型(ChatModel)对接阿里通义千问大模型,是智能体的「大脑」,负责推理决策:private static ChatModel getChatModel() { // 构建通义千问API客户端 DashScopeApi dashScopeApi = DashScopeApi.builder() .apiKey(System.getenv("AliQwen_API")) // 环境变量配置API Key .build(); // 创建对话模型 return DashScopeChatModel.builder() .dashScopeApi(dashScopeApi) .build(); }2.2 技能注册中心(SkillRegistry)负责加载、管理所有技能,Spring AI Alibaba 提供两种常用实现:ClasspathSkillRegistry:从项目类路径(resources)加载技能FileSystemSkillRegistry:从本地文件系统加载技能代码示例:SkillRegistry registry = ClasspathSkillRegistry.builder() .classpathPath("skills") // 指向resources/skills目录 .build();2.3 技能钩子(SkillsAgentHook)连接智能体与技能系统的桥梁,负责注入技能上下文、提供工具调用能力:SkillsAgentHook hook = SkillsAgentHook.builder() .skillRegistry(registry) // 绑定技能注册中心 .build();2.4 ReAct 智能体(ReactAgent)基于 ReAct(推理+执行) 模式的智能体,自主完成「思考→选技能→执行任务」的全流程:ReactAgent agent = ReactAgent.builder() .name("skills-agent") // 智能体名称 .model(chatModel) // 绑定大模型 .saver(new MemorySaver()) // 内存记忆(保存对话上下文) .hooks(List.of(hook)) // 绑定技能钩子 .build();三、实战场景场景一:技能发现(智能体自我认知)让AI智能体主动披露自身具备的所有技能,验证技能加载是否成功。核心代码private static void findSkills() throws GraphRunnerException { // 1. 初始化核心组件 ChatModel chatModel = getChatModel(); SkillsAgentHook hook = getSkillsAgentHook(); // 2. 构建技能智能体 ReactAgent agent = ReactAgent.builder() .name("skills-agent") .model(chatModel) .saver(new MemorySaver()) .hooks(List.of(hook)) .build(); // 3. 执行对话:查询技能 AssistantMessage resp = agent.call("请介绍你有哪些技能"); System.out.println(resp.getText()); }执行结果11:29:36.067 [main] INFO com.alibaba.cloud.ai.graph.skills.registry.classpath.ClasspathSkillRegistry -- Loaded 1 skills from classpath: skills 我目前拥有的技能包括: - **pdf-extractor**: 用于从 PDF 文档中提取文本、表格和表单数据,适用于分析和处理 PDF 文件。当用户需要提取、解析或分析 PDF 文件时可使用此技能。 如需了解某项技能的详细说明(例如具体操作步骤、支持的文件类型、使用示例等),我可以为您读取其完整的技能文档(`SKILL.md`)。您也可以告诉我您的具体需求(例如:“请帮我从一份PDF中提取所有表格”),我会判断是否适用某项技能并执行相应操作。 是否需要我为您详细展开某一项技能?场景二:技能使用(PDF 信息提取)结合技能系统 + Python 执行工具 + Shell 工具,实现多工具协作,完成 PDF 文本/表格提取。步骤1:自定义 Python 执行工具(GraalVM 支持)依赖如下<!-- GraalVM Polyglot for Python execution --> <dependency> <groupId>org.graalvm.polyglot</groupId> <artifactId>polyglot</artifactId> <version>24.2.1</version> </dependency> <dependency> <groupId>org.graalvm.polyglot</groupId> <artifactId>python-community</artifactId> <version>24.2.1</version> <type>pom</type> </dependency>用于执行 Python 脚本完成 PDF 解析,工具代码如下:package com.jcq.springaialibabaagent.tools; import com.fasterxml.jackson.annotation.JsonProperty; import com.fasterxml.jackson.annotation.JsonPropertyDescription; import org.graalvm.polyglot.Context; import org.graalvm.polyglot.Engine; import org.graalvm.polyglot.PolyglotException; import org.graalvm.polyglot.Value; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.ai.chat.model.ToolContext; import org.springframework.ai.tool.ToolCallback; import org.springframework.ai.tool.function.FunctionToolCallback; import java.util.function.BiFunction; /** * GraalVM 沙箱环境执行 Python 代码的工具 * 安全沙箱:禁用文件IO、进程创建、本地访问 */ public class PythonTool implements BiFunction<PythonTool.PythonRequest, ToolContext, String> { public static final String DESCRIPTION = """ Executes Python code and returns the result. - 代码必须为合法Python语法 - 沙箱执行,安全无风险 - 支持返回数字、字符串、数组、执行结果 """; private static final Logger log = LoggerFactory.getLogger(PythonTool.class); private final Engine engine; public PythonTool() { this.engine = Engine.newBuilder() .option("engine.WarnInterpreterOnly", "false") .build(); } /** 构建Spring AI 标准工具回调 */ public static ToolCallback createPythonToolCallback(String description) { return FunctionToolCallback.builder("python_tool", new PythonTool()) .description(description) .inputType(PythonRequest.class) .build(); } @Override public String apply(PythonRequest request, ToolContext toolContext) { if (request.code == null || request.code.trim().isEmpty()) { return "Error:Python代码不能为空"; } // 沙箱环境执行Python try (Context context = Context.newBuilder("python") .engine(engine) .allowAllAccess(false) .allowIO(false) .allowNativeAccess(false) .allowCreateProcess(false) .allowHostAccess(true) .build()) { log.debug("执行Python代码:{}", request.code); Value result = context.eval("python", request.code); // 结果类型转换 if (result.isNull()) return "执行完成,无返回值"; if (result.isString()) return result.asString(); if (result.isNumber() || result.isBoolean()) return result.toString(); if (result.hasArrayElements()) { StringBuilder sb = new StringBuilder("["); long size = result.getArraySize(); for (long i = 0; i < size; i++) { if (i > 0) sb.append(", "); sb.append(result.getArrayElement(i)); } return sb.append("]").toString(); } return result.toString(); } catch (PolyglotException e) { log.error("Python执行异常", e); return "执行错误:" + e.getMessage(); } } /** 工具请求参数 */ public static class PythonRequest { @JsonProperty(required = true) @JsonPropertyDescription("需要执行的Python代码") public String code; public PythonRequest() {} public PythonRequest(String code) { this.code = code; } } }步骤2:构建多技能协作智能体private static void useSkills() throws Exception { // 1. 初始化大模型 ChatModel chatModel = getChatModel(); // 2. 绑定技能钩子 + Shell工具钩子 SkillsAgentHook skillsHook = getSkillsAgentHook(); ShellToolAgentHook shellHook = ShellToolAgentHook.builder() .shellTool2(ShellTool2.builder(System.getProperty("user.dir")).build()) .build(); // 3. 构建智能体(绑定技能+工具+日志) ReactAgent agent = ReactAgent.builder() .name("skills-integration-agent") .model(chatModel) .saver(new MemorySaver()) .tools(PythonTool.createPythonToolCallback(PythonTool.DESCRIPTION)) // 自定义Python工具 .hooks(List.of(skillsHook, shellHook)) // 多钩子组合 .enableLogging(true) // 开启日志,便于调试 .build(); // 4. 执行PDF提取任务 String pdfPath = getTestSkillsDirectory() + "/pdf-extractor/skill-test.pdf"; AssistantMessage response = agent.call(String.format("请从 %s 文件中提取关键信息", pdfPath)); // 5. 输出结果 System.out.println("========== PDF提取结果 =========="); System.out.println(response.getText()); }执行结果========== The PDF extraction was successful! Here's the key information extracted from the `skill-test.pdf` file: ## Document Metadata - **Title**: Sample PDF Document - **Author**: Test Author - **Created**: 2024-01-01 - **Modified**: 2024-01-15 - **Page Count**: 5 pages ## Extracted Text The document contains: "This is extracted text from the PDF document. It contains multiple paragraphs and sections." ## Tables Found ### Table 1 (Page 1) - Product Inventory | Product | Price | Quantity | |---------|-------|----------| | Widget A | $10.00 | 100 | | Widget B | $15.00 | 50 | ### Table 2 (Page 3) - Financial Summary | Month | Revenue | Expenses | |-------|---------|----------| | January | $50,000 | $30,000 | | February | $55,000 | $32,000 |四、最佳实践建议技能规范化管理所有技能统一放在 resources/skills 目录,按业务拆分子目录;SKILL.md 严格遵循格式规范,保证模型准确识别。多钩子灵活组合基础能力:SkillsAgentHook(技能系统);系统操作:ShellToolAgentHook(Shell命令);自定义能力:自定义工具(Python/Java/第三方API)。开发与调试优化开发阶段开启 enableLogging(true),查看智能体推理全流程;测试使用 MemorySaver 快速验证,生产环境替换为持久化存储。模型选型策略简单技能查询:基础版通义千问;复杂工具协作/多步骤推理:高级版大模型。