搜索到
1
篇与
的结果
-
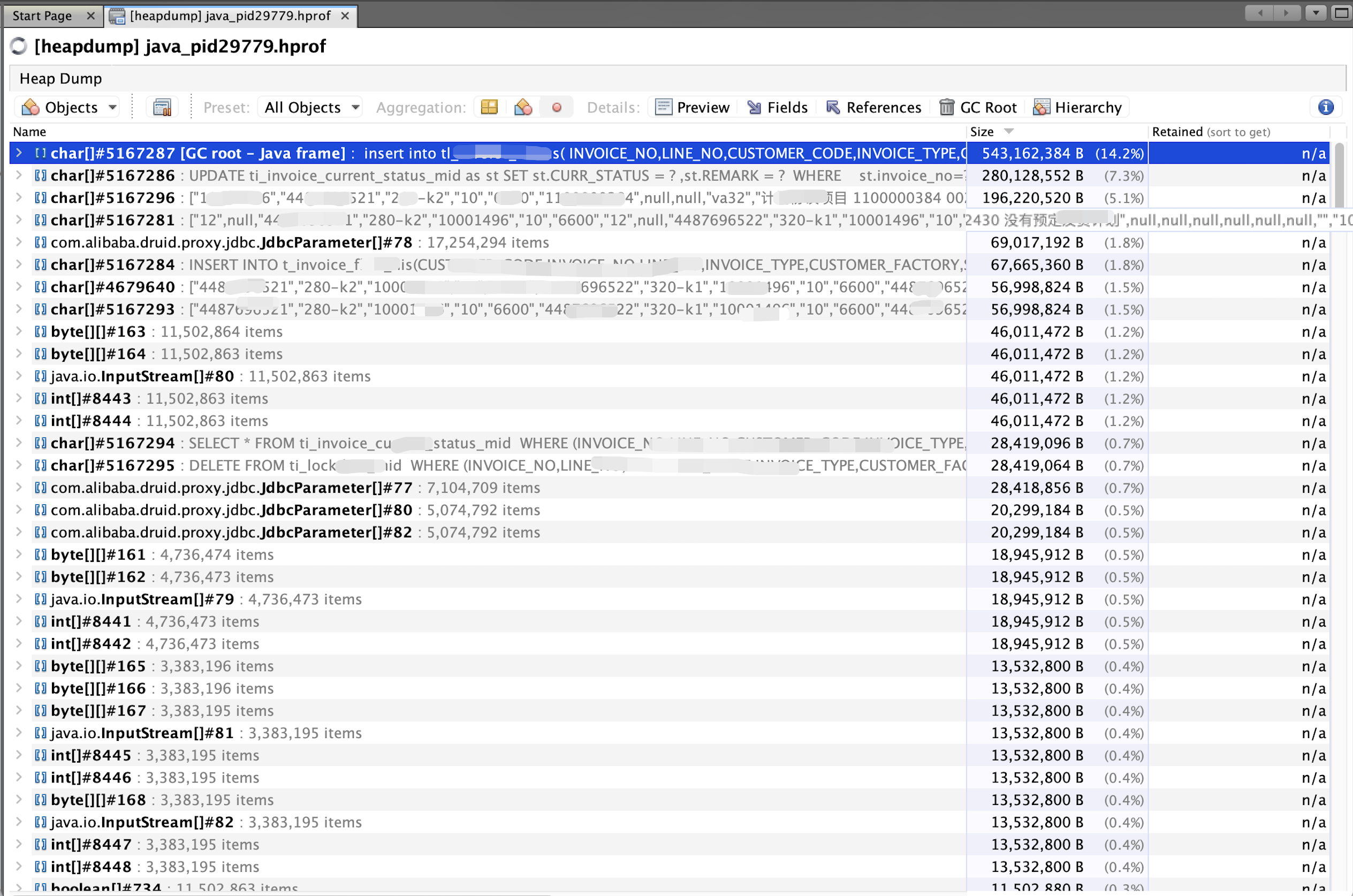
 一次 OOM 线上排查实录 大家好,今天分享一次真实的线上 OOM 排查过程,踩坑 Druid 连接池的经典内存泄漏问题,以及完整的解决思路。一、问题现场:线上内存飙高,OOM 报警某天,线上老项目突然收到服务器内存使用率持续飙高的报警,紧接着应用直接抛出 OOM 错误,服务崩溃。紧急拉取了堆 Dump 文件,用 JProfiler 打开后,直接看到了内存占用的元凶:大量 com.alibaba.druid.proxy.jdbc 相关对象堆积堆中最大的单个对象是一个 char[],大小超过 500MB,存储的正是项目中执行的 SQL 字符串结合项目业务场景,初步判断是数据库操作相关的内存泄漏,定位方向直接锁定了代码中的 SQL 操作和 Druid 连接池配置。二、根因定位:双重问题叠加导致的灾难顺着堆 Dump 里的 SQL 文本,我直接定位到了业务代码,发现这次 OOM 是两个问题叠加导致的。1. 业务代码:SQL 拼接逻辑导致大对象堆积这是一个老项目,当年的开发同学已经离职了,代码里存在这样的逻辑:单条 INSERT 语句中,通过循环拼接 SQL 字符串,一次性插入大量数据当数据量较大时,拼接后的 SQL 字符串会变得非常大,生成的 char[] 对象直接占用几百 MB 内存这些大字符串被线程栈引用,短时间内无法被 GC 回收,直接推高了内存水位2. 框架层面:Druid 1.1.22 版本的经典 SQL 缓存泄漏堆 Dump 中大量的 Druid 对象,指向了一个更致命的问题:Druid 连接池的 SQL 统计缓存。项目使用的 Druid 版本是 1.1.22,这个版本存在一个广为人知的问题:SQL 统计功能会无限制缓存所有执行过的 SQL 字符串,无法自动清理项目中拼接的大量不同 SQL,会被 Druid 全部缓存到 sqlStatMap 中,这些对象会一直持有 SQL 字符串的引用,导致它们无法被 GC 回收随着服务运行时间增长,缓存的 SQL 越来越多,内存只会涨不会跌,最终撑满堆内存,触发 OOM三、解决方案:两步走彻底根治问题针对这两个问题,我们采用了业务+框架双管齐下的修复方案,从根源解决内存泄漏。第一步:优化 Druid 配置,掐断缓存泄漏直接修改项目的 Druid 配置,关闭无限制的 SQL 统计,同时限制缓存大小,避免内存无限增长。方案 A:彻底关闭 SQL 统计(推荐,零泄漏风险)spring: datasource: druid: filter: stat: enabled: false # 关闭导致内存泄漏的SQL统计 web-stat-filter: enabled: false # 关闭Web统计,减少额外内存占用方案 B:保留监控,限制缓存大小(折中方案)如果业务必须保留 SQL 监控,可以通过配置限制缓存的 SQL 数量,避免无限增长:spring: datasource: druid: filter: stat: enabled: true max-stat-count: 200 # 限制最多缓存200条SQL,超出自动淘汰第二步:重构业务代码,替换 SQL 拼接为批量插入修改原有的 SQL 拼接逻辑,改为标准的批量插入方式,既避免了超大 SQL 字符串的生成,也提升了数据库写入性能。改造前(问题代码)// 循环拼接SQL,生成超大字符串 StringBuilder sql = new StringBuilder("INSERT INTO t_invoice (col1, col2) VALUES "); for (Invoice invoice : list) { sql.append("(?, ?),"); } jdbcTemplate.update(sql.toString(), params);改造后(批量插入)// 使用JdbcTemplate批量插入,避免生成超大SQL字符串 String sql = "INSERT INTO t_invoice (col1, col2) VALUES (?, ?)"; jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() { @Override public void setValues(PreparedStatement ps, int i) throws SQLException { ps.setString(1, list.get(i).getCol1()); ps.setString(2, list.get(i).getCol2()); } @Override public int getBatchSize() { return list.size(); } });四、效果验证与后续优化改造完成后,我们重新上线服务并进行了压测验证:内存曲线恢复平稳,不再出现持续飙高的情况堆 Dump 中 Druid 相关对象和大 char[] 基本消失数据库写入性能也有明显提升,单批次插入耗时降低了 40%额外优化建议对于老项目,建议升级 Druid 到最新稳定版(如 1.2.20+),修复了大量已知的内存泄漏问题批量插入时,建议设置合理的批次大小(如每批 100-500 条),避免单次操作过大导致数据库压力上线前务必进行压测,通过 JProfiler 或 Arthas 观察内存变化,提前发现潜在问题五、踩坑总结这次 OOM 排查给了我两个深刻的教训:老项目的依赖版本一定要关注:Druid 1.1.22 这个版本的 SQL 缓存泄漏问题非常普遍,很多线上 OOM 都源于此,升级或关闭统计是最直接的解决方式。业务代码的 SQL 拼接是隐形杀手:不仅容易导致 SQL 注入,还会生成超大对象,配合框架的缓存机制,很容易引发内存泄漏。批量插入是更安全、更高效的替代方案。希望这次分享能帮到遇到同样问题的朋友,如果你也遇到了 Druid 相关的内存问题,欢迎在评论区交流讨论~
一次 OOM 线上排查实录 大家好,今天分享一次真实的线上 OOM 排查过程,踩坑 Druid 连接池的经典内存泄漏问题,以及完整的解决思路。一、问题现场:线上内存飙高,OOM 报警某天,线上老项目突然收到服务器内存使用率持续飙高的报警,紧接着应用直接抛出 OOM 错误,服务崩溃。紧急拉取了堆 Dump 文件,用 JProfiler 打开后,直接看到了内存占用的元凶:大量 com.alibaba.druid.proxy.jdbc 相关对象堆积堆中最大的单个对象是一个 char[],大小超过 500MB,存储的正是项目中执行的 SQL 字符串结合项目业务场景,初步判断是数据库操作相关的内存泄漏,定位方向直接锁定了代码中的 SQL 操作和 Druid 连接池配置。二、根因定位:双重问题叠加导致的灾难顺着堆 Dump 里的 SQL 文本,我直接定位到了业务代码,发现这次 OOM 是两个问题叠加导致的。1. 业务代码:SQL 拼接逻辑导致大对象堆积这是一个老项目,当年的开发同学已经离职了,代码里存在这样的逻辑:单条 INSERT 语句中,通过循环拼接 SQL 字符串,一次性插入大量数据当数据量较大时,拼接后的 SQL 字符串会变得非常大,生成的 char[] 对象直接占用几百 MB 内存这些大字符串被线程栈引用,短时间内无法被 GC 回收,直接推高了内存水位2. 框架层面:Druid 1.1.22 版本的经典 SQL 缓存泄漏堆 Dump 中大量的 Druid 对象,指向了一个更致命的问题:Druid 连接池的 SQL 统计缓存。项目使用的 Druid 版本是 1.1.22,这个版本存在一个广为人知的问题:SQL 统计功能会无限制缓存所有执行过的 SQL 字符串,无法自动清理项目中拼接的大量不同 SQL,会被 Druid 全部缓存到 sqlStatMap 中,这些对象会一直持有 SQL 字符串的引用,导致它们无法被 GC 回收随着服务运行时间增长,缓存的 SQL 越来越多,内存只会涨不会跌,最终撑满堆内存,触发 OOM三、解决方案:两步走彻底根治问题针对这两个问题,我们采用了业务+框架双管齐下的修复方案,从根源解决内存泄漏。第一步:优化 Druid 配置,掐断缓存泄漏直接修改项目的 Druid 配置,关闭无限制的 SQL 统计,同时限制缓存大小,避免内存无限增长。方案 A:彻底关闭 SQL 统计(推荐,零泄漏风险)spring: datasource: druid: filter: stat: enabled: false # 关闭导致内存泄漏的SQL统计 web-stat-filter: enabled: false # 关闭Web统计,减少额外内存占用方案 B:保留监控,限制缓存大小(折中方案)如果业务必须保留 SQL 监控,可以通过配置限制缓存的 SQL 数量,避免无限增长:spring: datasource: druid: filter: stat: enabled: true max-stat-count: 200 # 限制最多缓存200条SQL,超出自动淘汰第二步:重构业务代码,替换 SQL 拼接为批量插入修改原有的 SQL 拼接逻辑,改为标准的批量插入方式,既避免了超大 SQL 字符串的生成,也提升了数据库写入性能。改造前(问题代码)// 循环拼接SQL,生成超大字符串 StringBuilder sql = new StringBuilder("INSERT INTO t_invoice (col1, col2) VALUES "); for (Invoice invoice : list) { sql.append("(?, ?),"); } jdbcTemplate.update(sql.toString(), params);改造后(批量插入)// 使用JdbcTemplate批量插入,避免生成超大SQL字符串 String sql = "INSERT INTO t_invoice (col1, col2) VALUES (?, ?)"; jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() { @Override public void setValues(PreparedStatement ps, int i) throws SQLException { ps.setString(1, list.get(i).getCol1()); ps.setString(2, list.get(i).getCol2()); } @Override public int getBatchSize() { return list.size(); } });四、效果验证与后续优化改造完成后,我们重新上线服务并进行了压测验证:内存曲线恢复平稳,不再出现持续飙高的情况堆 Dump 中 Druid 相关对象和大 char[] 基本消失数据库写入性能也有明显提升,单批次插入耗时降低了 40%额外优化建议对于老项目,建议升级 Druid 到最新稳定版(如 1.2.20+),修复了大量已知的内存泄漏问题批量插入时,建议设置合理的批次大小(如每批 100-500 条),避免单次操作过大导致数据库压力上线前务必进行压测,通过 JProfiler 或 Arthas 观察内存变化,提前发现潜在问题五、踩坑总结这次 OOM 排查给了我两个深刻的教训:老项目的依赖版本一定要关注:Druid 1.1.22 这个版本的 SQL 缓存泄漏问题非常普遍,很多线上 OOM 都源于此,升级或关闭统计是最直接的解决方式。业务代码的 SQL 拼接是隐形杀手:不仅容易导致 SQL 注入,还会生成超大对象,配合框架的缓存机制,很容易引发内存泄漏。批量插入是更安全、更高效的替代方案。希望这次分享能帮到遇到同样问题的朋友,如果你也遇到了 Druid 相关的内存问题,欢迎在评论区交流讨论~