搜索到
3
篇与
的结果
-
 Spring Retry 重试机制:优雅解决接口调用失败问题 在日常开发中,我们经常会遇到第三方接口不稳定、网络抖动导致的调用失败场景。很多人第一反应是在 try-catch 里写 for 循环重试,再搭配 Thread.sleep() 控制间隔——这种写法不仅冗余,还难以维护。今天给大家推荐 Spring Retry 框架,它基于 AOP 实现,能让你零侵入式地为方法添加重试功能,大幅简化代码!一、快速上手:三步集成 Spring Retry1. 添加 Maven 依赖Spring Retry 核心依赖 + AOP 依赖(因为其底层是 AOP 实现),这里推荐使用 2.0.12 稳定版本:<!-- Spring Retry 核心依赖 --> <dependency> <groupId>org.springframework.retry</groupId> <artifactId>spring-retry</artifactId> <version>2.0.12</version> </dependency> <!-- AOP 依赖(Spring Boot 项目推荐此 starter) --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency>2. 启用 Spring Retry 功能在 Spring Boot 主启动类上添加 @EnableRetry 注解,一键开启重试功能:import org.springframework.retry.annotation.EnableRetry; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @EnableRetry // 启用重试功能 @SpringBootApplication public class SpringRetryDemoApplication { public static void main(String[] args) { SpringApplication.run(SpringRetryDemoApplication.class, args); } }3. 核心注解:@Retryable 标记重试方法在需要重试的方法上添加 @Retryable 注解,即可实现重试逻辑。基础用法import org.springframework.retry.annotation.Retryable; import org.springframework.stereotype.Service; @Service public class RetryDemoService { // 标记该方法需要重试 @Retryable public void basicRetry() { int random = (int) (Math.random() * 10); System.out.println("当前随机数:" + random); // 模拟异常:随机数为偶数时抛出异常 if (random % 2 == 0) { throw new RuntimeException("随机数为偶数,触发异常"); } System.out.println("方法执行成功!"); } }基础用法说明未指定异常类型时,方法抛出任何异常都会触发重试。默认重试次数:3次(包含首次执行,实际重试 2 次)。默认重试间隔:1秒。当重试次数耗尽仍失败时,会抛出 ExhaustedRetryException 异常。二、进阶配置:灵活定制重试策略@Retryable 注解提供了丰富的属性,可根据业务需求精准控制重试逻辑。1. @Retryable 核心属性说明属性名作用示例value/retryFor指定触发重试的异常类型retryFor = RuntimeException.classinclude同 value,优先级更高include = {NullPointerException.class}exclude指定不触发重试的异常类型exclude = IllegalArgumentException.classmaxAttempts最大重试次数(包含首次执行)maxAttempts = 5backoff配置重试间隔策略@Backoff(delay = 1000, multiplier = 2)stateful是否有状态重试(异常信息保留)stateful = true2. 实战示例:指数退避重试需求:调用第三方接口时,仅在抛出 RuntimeException 时重试,最大重试 5 次,重试间隔按 1s → 2s → 4s → 8s 指数增长(避免高频重试压垮接口)。import org.springframework.retry.annotation.Backoff; import org.springframework.retry.annotation.Retryable; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class RetryDemoController { @GetMapping("/test/retry") // 仅对RuntimeException重试,最大5次,指数退避间隔 @Retryable( retryFor = RuntimeException.class, maxAttempts = 5, backoff = @Backoff(delay = 1000, multiplier = 2.0) ) public String testRetry() { int random = (int) (Math.random() * 10); System.out.println("[" + System.currentTimeMillis() + "] 当前随机数:" + random); if (random % 2 == 0) { throw new RuntimeException("随机数为偶数,触发重试"); } return "调用成功!随机数:" + random; } }三、兜底处理:@Recover 重试失败后的恢复逻辑当重试次数耗尽仍失败时,我们需要一个兜底方法来处理最终的失败(比如记录日志、返回默认结果),这时候就需要 @Recover 注解。1. @Recover 用法规则恢复方法和 @Retryable 方法应该在同一个类中。后续参数需和 @Retryable 方法的参数列表完全一致。返回值需和 @Retryable 方法的返回值完全一致。2. 实战示例:重试失败后返回默认结果import org.springframework.retry.annotation.Recover; import org.springframework.retry.annotation.Retryable; import org.springframework.stereotype.Service; @Service public class RetryDemoService { @Retryable( retryFor = RuntimeException.class, maxAttempts = 3, backoff = @Backoff(delay = 1000) ) public String callThirdPartyApi(String param) { System.out.println("调用第三方接口,参数:" + param); // 模拟接口调用失败 throw new RuntimeException("第三方接口超时"); } // 重试失败后的恢复方法 @Recover public String recover(RuntimeException e, String param) { System.out.println("重试次数耗尽,执行兜底逻辑!异常信息:" + e.getMessage()); System.out.println("请求参数:" + param); // 返回默认结果 return "接口调用失败,已触发兜底策略"; } }四、注意事项(避坑指南)@Retryable 不能修饰 private 方法:因为 Spring AOP 无法代理 private 方法,重试逻辑会失效。避免同类方法调用:如果在同一个类中调用 @Retryable 方法(非代理调用),重试逻辑也会失效。重试策略要合理:避免设置过短的间隔和过多的重试次数,增加服务压力。五、总结Spring Retry 凭借注解化的方式,让我们摆脱了手写重试逻辑的繁琐,实现了代码的优雅和解耦。核心要点如下:三步集成:加依赖 → 启注解 → 标记方法。灵活配置:通过 @Retryable 属性定制重试次数、间隔、触发异常。兜底保障:通过 @Recover 处理重试失败的最终逻辑。掌握 Spring Retry,能让你在应对不稳定接口时更加从容,大幅提升系统的健壮性!
Spring Retry 重试机制:优雅解决接口调用失败问题 在日常开发中,我们经常会遇到第三方接口不稳定、网络抖动导致的调用失败场景。很多人第一反应是在 try-catch 里写 for 循环重试,再搭配 Thread.sleep() 控制间隔——这种写法不仅冗余,还难以维护。今天给大家推荐 Spring Retry 框架,它基于 AOP 实现,能让你零侵入式地为方法添加重试功能,大幅简化代码!一、快速上手:三步集成 Spring Retry1. 添加 Maven 依赖Spring Retry 核心依赖 + AOP 依赖(因为其底层是 AOP 实现),这里推荐使用 2.0.12 稳定版本:<!-- Spring Retry 核心依赖 --> <dependency> <groupId>org.springframework.retry</groupId> <artifactId>spring-retry</artifactId> <version>2.0.12</version> </dependency> <!-- AOP 依赖(Spring Boot 项目推荐此 starter) --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency>2. 启用 Spring Retry 功能在 Spring Boot 主启动类上添加 @EnableRetry 注解,一键开启重试功能:import org.springframework.retry.annotation.EnableRetry; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @EnableRetry // 启用重试功能 @SpringBootApplication public class SpringRetryDemoApplication { public static void main(String[] args) { SpringApplication.run(SpringRetryDemoApplication.class, args); } }3. 核心注解:@Retryable 标记重试方法在需要重试的方法上添加 @Retryable 注解,即可实现重试逻辑。基础用法import org.springframework.retry.annotation.Retryable; import org.springframework.stereotype.Service; @Service public class RetryDemoService { // 标记该方法需要重试 @Retryable public void basicRetry() { int random = (int) (Math.random() * 10); System.out.println("当前随机数:" + random); // 模拟异常:随机数为偶数时抛出异常 if (random % 2 == 0) { throw new RuntimeException("随机数为偶数,触发异常"); } System.out.println("方法执行成功!"); } }基础用法说明未指定异常类型时,方法抛出任何异常都会触发重试。默认重试次数:3次(包含首次执行,实际重试 2 次)。默认重试间隔:1秒。当重试次数耗尽仍失败时,会抛出 ExhaustedRetryException 异常。二、进阶配置:灵活定制重试策略@Retryable 注解提供了丰富的属性,可根据业务需求精准控制重试逻辑。1. @Retryable 核心属性说明属性名作用示例value/retryFor指定触发重试的异常类型retryFor = RuntimeException.classinclude同 value,优先级更高include = {NullPointerException.class}exclude指定不触发重试的异常类型exclude = IllegalArgumentException.classmaxAttempts最大重试次数(包含首次执行)maxAttempts = 5backoff配置重试间隔策略@Backoff(delay = 1000, multiplier = 2)stateful是否有状态重试(异常信息保留)stateful = true2. 实战示例:指数退避重试需求:调用第三方接口时,仅在抛出 RuntimeException 时重试,最大重试 5 次,重试间隔按 1s → 2s → 4s → 8s 指数增长(避免高频重试压垮接口)。import org.springframework.retry.annotation.Backoff; import org.springframework.retry.annotation.Retryable; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class RetryDemoController { @GetMapping("/test/retry") // 仅对RuntimeException重试,最大5次,指数退避间隔 @Retryable( retryFor = RuntimeException.class, maxAttempts = 5, backoff = @Backoff(delay = 1000, multiplier = 2.0) ) public String testRetry() { int random = (int) (Math.random() * 10); System.out.println("[" + System.currentTimeMillis() + "] 当前随机数:" + random); if (random % 2 == 0) { throw new RuntimeException("随机数为偶数,触发重试"); } return "调用成功!随机数:" + random; } }三、兜底处理:@Recover 重试失败后的恢复逻辑当重试次数耗尽仍失败时,我们需要一个兜底方法来处理最终的失败(比如记录日志、返回默认结果),这时候就需要 @Recover 注解。1. @Recover 用法规则恢复方法和 @Retryable 方法应该在同一个类中。后续参数需和 @Retryable 方法的参数列表完全一致。返回值需和 @Retryable 方法的返回值完全一致。2. 实战示例:重试失败后返回默认结果import org.springframework.retry.annotation.Recover; import org.springframework.retry.annotation.Retryable; import org.springframework.stereotype.Service; @Service public class RetryDemoService { @Retryable( retryFor = RuntimeException.class, maxAttempts = 3, backoff = @Backoff(delay = 1000) ) public String callThirdPartyApi(String param) { System.out.println("调用第三方接口,参数:" + param); // 模拟接口调用失败 throw new RuntimeException("第三方接口超时"); } // 重试失败后的恢复方法 @Recover public String recover(RuntimeException e, String param) { System.out.println("重试次数耗尽,执行兜底逻辑!异常信息:" + e.getMessage()); System.out.println("请求参数:" + param); // 返回默认结果 return "接口调用失败,已触发兜底策略"; } }四、注意事项(避坑指南)@Retryable 不能修饰 private 方法:因为 Spring AOP 无法代理 private 方法,重试逻辑会失效。避免同类方法调用:如果在同一个类中调用 @Retryable 方法(非代理调用),重试逻辑也会失效。重试策略要合理:避免设置过短的间隔和过多的重试次数,增加服务压力。五、总结Spring Retry 凭借注解化的方式,让我们摆脱了手写重试逻辑的繁琐,实现了代码的优雅和解耦。核心要点如下:三步集成:加依赖 → 启注解 → 标记方法。灵活配置:通过 @Retryable 属性定制重试次数、间隔、触发异常。兜底保障:通过 @Recover 处理重试失败的最终逻辑。掌握 Spring Retry,能让你在应对不稳定接口时更加从容,大幅提升系统的健壮性! -
Spring AI Tool 工具方法调用源码深度解析:从流式交互到工具执行全流程 Spring AI Tool 工具方法调用源码深度解析:从流式交互到工具执行全流程前言:为什么需要读源码?如何高效读源码?在上一篇博客中,我们介绍了如何通过 Spring AI 快速调用本地 Tool 方法实现大模型的工具能力扩展。但对于开发者来说,仅仅会用还不够 —— 理解框架的底层逻辑,才能在遇到问题时快速定位、在定制需求时游刃有余。博客链接:https://www.lucaju.cn/index.php/archives/131/很多小伙伴对读源码望而却步,其实掌握方法就能事半功倍:详略得当:聚焦核心业务逻辑,忽略日志、校验等辅助代码从命名和注释入手:规范框架的源码命名和注释会清晰指引核心流程由浅入深:先抓整体流程,再钻关键细节,避免一开始陷入代码迷宫本文将从 Spring AI 调用大模型的业务代码出发,逐步深入源码,解析 Tool 工具方法调用的完整流程,重点剖析工具执行的核心逻辑。1. 业务代码回顾:流式调用大模型的入口先看一段典型的 Spring AI 流式调用大模型并启用工具的业务代码,这是我们源码解析的起点:public Flux<String> stream(String content) { // 创建chatModel对象,配置模型参数和工具回调管理器 OpenAiChatModel chatModel = OpenAiChatModel.builder() .openAiApi(OpenAiApi.builder() .baseUrl("https://api.siliconflow.cn") .apiKey(System.getenv("SiliconFlow_API")) .build()) .defaultOptions(OpenAiChatOptions.builder() .model("Qwen/Qwen3-8B") .build()) // 关键:配置工具调用管理器 .toolCallingManager(SpringUtil.getBean(ToolCallingManager.class)) .build(); // 创建prompt对象 Prompt prompt = new Prompt(content); // 调用流式输出接口 Flux<ChatResponse> stream = chatModel.stream(prompt); return stream.map(chunk -> { String text = chunk.getResult() != null ? chunk.getResult().getOutput() != null ? chunk.getResult().getOutput().getText() : "" : ""; text = StrUtil.nullToDefault(text, ""); return text; }); }核心逻辑很清晰:创建配置好的OpenAiChatModel,构造Prompt,调用stream方法获取流式响应。其中toolCallingManager的配置是启用工具调用的关键。2. 入口:ChatModel 的 stream 方法从业务代码的chatModel.stream(prompt)进入源码,这是整个流程的入口:@Override public Flux<ChatResponse> stream(Prompt prompt) { // 合并运行时和默认选项,创建最终请求prompt Prompt requestPrompt = buildRequestPrompt(prompt); // 实际发起请求 return internalStream(requestPrompt, null); }2.1 配置合并:buildRequestPrompt 方法buildRequestPrompt的核心作用是合并运行时配置和默认配置,确保模型使用正确的参数(如工具列表、回调、上下文等):Prompt buildRequestPrompt(Prompt prompt) { // 处理运行时prompt options OpenAiChatOptions runtimeOptions = null; if (prompt.getOptions() != null) { // 转换运行时选项为OpenAiChatOptions类型 if (prompt.getOptions() instanceof ToolCallingChatOptions toolCallingChatOptions) { runtimeOptions = ModelOptionsUtils.copyToTarget(toolCallingChatOptions, ToolCallingChatOptions.class, OpenAiChatOptions.class); } else { runtimeOptions = ModelOptionsUtils.copyToTarget(prompt.getOptions(), ChatOptions.class, OpenAiChatOptions.class); } } // 合并运行时选项和默认选项 OpenAiChatOptions requestOptions = ModelOptionsUtils.merge(runtimeOptions, this.defaultOptions, OpenAiChatOptions.class); // 显式合并特殊选项(如HTTP头、工具配置等) if (runtimeOptions != null) { requestOptions.setHttpHeaders(mergeHttpHeaders(runtimeOptions.getHttpHeaders(), this.defaultOptions.getHttpHeaders())); requestOptions.setInternalToolExecutionEnabled( ModelOptionsUtils.mergeOption(runtimeOptions.getInternalToolExecutionEnabled(), this.defaultOptions.getInternalToolExecutionEnabled())); // 合并工具名称、回调、上下文等关键配置 requestOptions.setToolNames(ToolCallingChatOptions.mergeToolNames(runtimeOptions.getToolNames(), this.defaultOptions.getToolNames())); requestOptions.setToolCallbacks(ToolCallingChatOptions.mergeToolCallbacks(runtimeOptions.getToolCallbacks(), this.defaultOptions.getToolCallbacks())); requestOptions.setToolContext(ToolCallingChatOptions.mergeToolContext(runtimeOptions.getToolContext(), this.defaultOptions.getToolContext())); } else { // 若无可运行时选项,直接使用默认配置 requestOptions.setHttpHeaders(this.defaultOptions.getHttpHeaders()); requestOptions.setInternalToolExecutionEnabled(this.defaultOptions.getInternalToolExecutionEnabled()); requestOptions.setToolNames(this.defaultOptions.getToolNames()); requestOptions.setToolCallbacks(this.defaultOptions.getToolCallbacks()); requestOptions.setToolContext(this.defaultOptions.getToolContext()); } // 校验工具回调配置 ToolCallingChatOptions.validateToolCallbacks(requestOptions.getToolCallbacks()); return new Prompt(prompt.getInstructions(), requestOptions); }总结:该方法通过合并默认配置和运行时配置,生成最终的请求参数,确保工具调用相关的配置(工具列表、回调等)被正确传入。3. 核心流程:internalStream 方法的完整解析internalStream是实际处理流式请求的核心方法,流程可拆解为 7 个关键步骤。我们重点关注与工具调用相关的核心逻辑:return Flux.deferContextual(contextView -> { // 步骤一:生成请求request对象 ChatCompletionRequest request = createRequest(prompt, true); // 步骤二:语音类型流式输出校验(非核心,略) audioRequestCheck()... // 步骤三:发送调用请求,获取流式响应 Flux<OpenAiApi.ChatCompletionChunk> completionChunks = this.openAiApi.chatCompletionStream(request, getAdditionalHttpHeaders(prompt)); // 步骤四:角色缓存(非核心,略) ConcurrentHashMap<String, String> roleMap = new ConcurrentHashMap<>(); // 步骤五:生成监控observation对象(非核心,略) final ChatModelObservationContext observationContext = ...; Observation observation = ...; // 步骤六:转换响应格式(将分片转为ChatResponse) Flux<ChatResponse> chatResponse = completionChunks.map()...... // 步骤七:处理聊天响应流(核心:工具调用逻辑在这里) Flux<ChatResponse> flux = chatResponse.flatMap()...... return new MessageAggregator().aggregate(flux, observationContext::setResponse); });3.1 步骤三:发送流式请求(chatCompletionStream)chatCompletionStream负责向大模型 API 发送流式请求,并处理服务器返回的 SSE(Server-Sent Events)响应:public Flux<ChatCompletionChunk> chatCompletionStream(ChatCompletionRequest chatRequest, MultiValueMap<String, String> additionalHttpHeader) { // 断言校验:请求非空且流式开关为true Assert.notNull(chatRequest, "The request body can not be null."); Assert.isTrue(chatRequest.stream(), "Request must set the stream property to true."); AtomicBoolean isInsideTool = new AtomicBoolean(false); // 使用WebClient发送POST请求,处理流式响应 return this.webClient.post() .uri(this.completionsPath) .headers(headers -> headers.addAll(additionalHttpHeader)) .body(Mono.just(chatRequest), ChatCompletionRequest.class) .retrieve() // 将响应转为字符串流 .bodyToFlux(String.class) // 终止条件:收到"[DONE]" .takeUntil("[DONE]"::equals) // 过滤掉终止符 .filter("[DONE]"::equals.negate()) // 转换为ChatCompletionChunk对象 .map(content -> ModelOptionsUtils.jsonToObject(content, ChatCompletionChunk.class)) // 标记工具调用片段(关键:识别工具调用的分片) .map(chunk -> { if (this.chunkMerger.isStreamingToolFunctionCall(chunk)) { isInsideTool.set(true); } return chunk; }) // 窗口化合并工具调用分片(核心:合并工具调用的多个分片) .windowUntil(chunk -> { if (isInsideTool.get() && this.chunkMerger.isStreamingToolFunctionCallFinish(chunk)) { isInsideTool.set(false); return true; } return !isInsideTool.get(); }) // 合并分片内容 .concatMapIterable(window -> { Mono<ChatCompletionChunk> monoChunk = window.reduce( new ChatCompletionChunk(...), (previous, current) -> this.chunkMerger.merge(previous, current)); return List.of(monoChunk); }) .flatMap(mono -> mono); }为什么需要合并分片?大模型返回工具调用时,可能会将工具名称、参数等拆分到多个 SSE 分片中(如下例)。windowUntil和reduce通过finish_reason=tool_calls标记合并分片,确保工具调用信息完整。// 分片1:工具调用开始 { "choices": [{"delta": {"tool_calls": [{"name": "current_date", "arguments": ""}]}}] } // 分片2:工具调用结束 { "choices": [{"delta": {}, "finish_reason": "tool_calls"}] }3.2 步骤六:响应格式转换(ChatResponse 处理)这一步将模型返回的ChatCompletionChunk转换为 Spring AI 统一的ChatResponse格式,同时处理 token 用量统计:Flux<ChatResponse> chatResponse = completionChunks // 转换为ChatCompletion对象 .map(this::chunkToChatCompletion) // 构建ChatResponse .switchMap(chatCompletion -> Mono.just(chatCompletion).map(chatCompletion2 -> { try { String id = chatCompletion2.id() == null ? "NO_ID" : chatCompletion2.id(); // 转换为Generation列表(核心数据) List<Generation> generations = chatCompletion2.choices().stream().map(choice -> { // 缓存角色信息 if (choice.message().role() != null) { roleMap.putIfAbsent(id, choice.message().role().name()); } // 构建元数据(ID、角色、完成原因等) Map<String, Object> metadata = Map.of( "id", id, "role", roleMap.getOrDefault(id, ""), "index", choice.index() != null ? choice.index() : 0, "finishReason", choice.finishReason() != null ? choice.finishReason().name() : ""); return buildGeneration(choice, metadata, request); }).toList(); // 处理token用量统计(流式模式下用量通常在最后返回) OpenAiApi.Usage usage = chatCompletion2.usage(); Usage currentChatResponseUsage = usage != null ? getDefaultUsage(usage) : new EmptyUsage(); Usage accumulatedUsage = UsageCalculator.getCumulativeUsage(currentChatResponseUsage, previousChatResponse); return new ChatResponse(generations, from(chatCompletion2, null, accumulatedUsage)); } catch (Exception e) { log.error("Error processing chat completion", e); return new ChatResponse(List.of()); } })) // 滑动窗口解决流式用量延迟问题 .buffer(2, 1) .map(bufferList -> { ChatResponse firstResponse = bufferList.get(0); if (request.streamOptions() != null && request.streamOptions().includeUsage()) { if (bufferList.size() == 2) { ChatResponse secondResponse = bufferList.get(1); // 用下一个响应的usage更新当前响应 Usage usage = secondResponse.getMetadata().getUsage(); if (!UsageCalculator.isEmpty(usage)) { return new ChatResponse(firstResponse.getResults(), from(firstResponse.getMetadata(), usage)); } } } return firstResponse; });总结:该步骤完成格式转换和用量统计,为后续工具调用判断提供标准化的ChatResponse对象。3.3 核心:Tool 工具方法的调用逻辑(步骤七详解)步骤七是工具调用的核心触发点,通过判断响应是否需要工具执行,决定是否调用ToolCallingManager:Flux<ChatResponse> flux = chatResponse.flatMap(response -> { // 判断是否需要执行工具调用(核心条件) if (this.toolExecutionEligibilityPredicate.isToolExecutionRequired(prompt.getOptions(), response)) { return Flux.defer(() -> { // 执行工具调用(同步操作) var toolExecutionResult = this.toolCallingManager.executeToolCalls(prompt, response); // 判断是否直接返回工具结果给客户端 if (toolExecutionResult.returnDirect()) { return Flux.just(ChatResponse.builder().from(response) .generations(ToolExecutionResult.buildGenerations(toolExecutionResult)) .build()); } else { // 不直接返回:将工具结果作为新输入继续请求模型 return this.internalStream(new Prompt(toolExecutionResult.conversationHistory(), prompt.getOptions()), response,false); } }).subscribeOn(Schedulers.boundedElastic()); } else { // 无需工具调用,直接返回原响应 return Flux.just(response); } }) // 监控相关处理(略) .doOnError(observation::error) .doFinally(s -> observation.stop()) .contextWrite(ctx -> ctx.put(ObservationThreadLocalAccessor.KEY, observation));3.3.1 工具调用的执行:executeToolCalls进入DefaultToolCallingManager的executeToolCalls方法,这是工具调用的统筹逻辑:@Override public ToolExecutionResult executeToolCalls(Prompt prompt, ChatResponse chatResponse) { // 验证输入 Assert.notNull(prompt, "prompt cannot be null"); Assert.notNull(chatResponse, "chatResponse cannot be null"); // 查找包含工具调用的响应 Optional<Generation> toolCallGeneration = chatResponse.getResults() .stream() .filter(g -> !CollectionUtils.isEmpty(g.getOutput().getToolCalls())) .findFirst(); if (toolCallGeneration.isEmpty()) { throw new IllegalStateException("No tool call requested by the chat model"); } AssistantMessage assistantMessage = toolCallGeneration.get().getOutput(); // 构建工具上下文 ToolContext toolContext = buildToolContext(prompt, assistantMessage); // 实际执行工具调用 InternalToolExecutionResult internalToolExecutionResult = executeToolCall(prompt, assistantMessage, toolContext); // 构建工具执行后的对话历史 List<Message> conversationHistory = buildConversationHistoryAfterToolExecution(prompt.getInstructions(), assistantMessage, internalToolExecutionResult.toolResponseMessage()); return ToolExecutionResult.builder() .conversationHistory(conversationHistory) .returnDirect(internalToolExecutionResult.returnDirect()) .build(); }3.3.2 工具调用的核心执行:executeToolCallexecuteToolCall是工具方法实际被调用的地方,负责匹配工具、执行调用、收集结果:private InternalToolExecutionResult executeToolCall(Prompt prompt, AssistantMessage assistantMessage, ToolContext toolContext) { // 从配置中获取工具回调列表 List<ToolCallback> toolCallbacks = List.of(); if (prompt.getOptions() instanceof ToolCallingChatOptions toolCallingChatOptions) { toolCallbacks = toolCallingChatOptions.getToolCallbacks(); } // 存储工具响应结果 List<ToolResponseMessage.ToolResponse> toolResponses = new ArrayList<>(); // 标记是否直接返回结果 Boolean returnDirect = null; // 遍历执行每个工具调用 for (AssistantMessage.ToolCall toolCall : assistantMessage.getToolCalls()) { // 提取工具名称和参数 String toolName = toolCall.name(); String toolInputArguments = toolCall.arguments(); // 匹配对应的ToolCallback(工具实现) ToolCallback toolCallback = toolCallbacks.stream() .filter(tool -> toolName.equals(tool.getToolDefinition().name())) .findFirst() .orElseGet(() -> this.toolCallbackResolver.resolve(toolName)); if (toolCallback == null) { throw new IllegalStateException("No ToolCallback found for tool name: " + toolName); } // 处理returnDirect标记(所有工具都要求直接返回才为true) if (returnDirect == null) { returnDirect = toolCallback.getToolMetadata().returnDirect(); } else { returnDirect = returnDirect && toolCallback.getToolMetadata().returnDirect(); } // 构建监控上下文 ToolCallingObservationContext observationContext = ToolCallingObservationContext.builder() .toolDefinition(toolCallback.getToolDefinition()) .toolMetadata(toolCallback.getToolMetadata()) .toolCallArguments(toolInputArguments) .build(); // 执行工具调用(含监控) String toolCallResult = ToolCallingObservationDocumentation.TOOL_CALL .observation(...) .observe(() -> { String toolResult; try { // 核心:调用工具的call方法执行实际逻辑 toolResult = toolCallback.call(toolInputArguments, toolContext); } catch (ToolExecutionException ex) { // 处理工具执行异常 toolResult = this.toolExecutionExceptionProcessor.process(ex); } observationContext.setToolCallResult(toolResult); return toolResult; }); // 收集工具响应 toolResponses.add(new ToolResponseMessage.ToolResponse(toolCall.id(), toolName, toolCallResult != null ? toolCallResult : "")); } // 返回执行结果 return new InternalToolExecutionResult(new ToolResponseMessage(toolResponses, Map.of()), returnDirect); }总结:从响应中提取工具调用信息(名称、参数);通过ToolCallback匹配对应的工具实现;调用工具的call方法执行实际逻辑(如查询数据库、调用 API 等);收集工具执行结果,构建新的对话历史;根据returnDirect决定是否直接返回结果或继续请求模型。最后再来看一下call方法,比较简单,就是执行我们的Tool工具方法逻辑啦@Override public String call(String toolInput, @Nullable ToolContext toolContext) { Assert.hasText(toolInput, "toolInput cannot be null or empty"); logger.debug("Starting execution of tool: {}", this.toolDefinition.name()); I request = JsonParser.fromJson(toolInput, this.toolInputType); O response = this.toolFunction.apply(request, toolContext); logger.debug("Successful execution of tool: {}", this.toolDefinition.name()); return this.toolCallResultConverter.convert(response, null); }4. 整体流程梳理:Tool 调用的完整链路结合源码解析,Spring AI Tool 工具调用的完整流程可概括为:配置准备:合并默认配置与运行时配置,生成包含工具信息的Prompt;模型请求:通过chatCompletionStream向大模型发送流式请求,获取 SSE 响应;分片处理:合并工具调用相关的分片,确保工具信息完整;格式转换:将模型响应转为ChatResponse,标准化数据格式;工具判断:检查响应是否包含工具调用请求;工具执行:通过ToolCallingManager匹配工具实现,执行call方法获取结果;结果处理:根据配置返回工具结果或用结果继续请求模型,形成对话闭环。结语本文从业务代码出发,逐步深入 Spring AI 的源码细节,重点解析了 Tool 工具方法调用的核心逻辑。理解这一流程后,你不仅能更清晰地排查工具调用中的问题,还能基于源码实现自定义扩展(如自定义工具匹配逻辑、增强异常处理等)。源码阅读的关键在于 “抓大放小”,先理清整体流程,再深入核心细节。希望本文的解析方式能帮助你更高效地学习框架源码,真正做到 “知其然,更知其所以然”。如果有疑问或补充,欢迎在评论区交流!
-
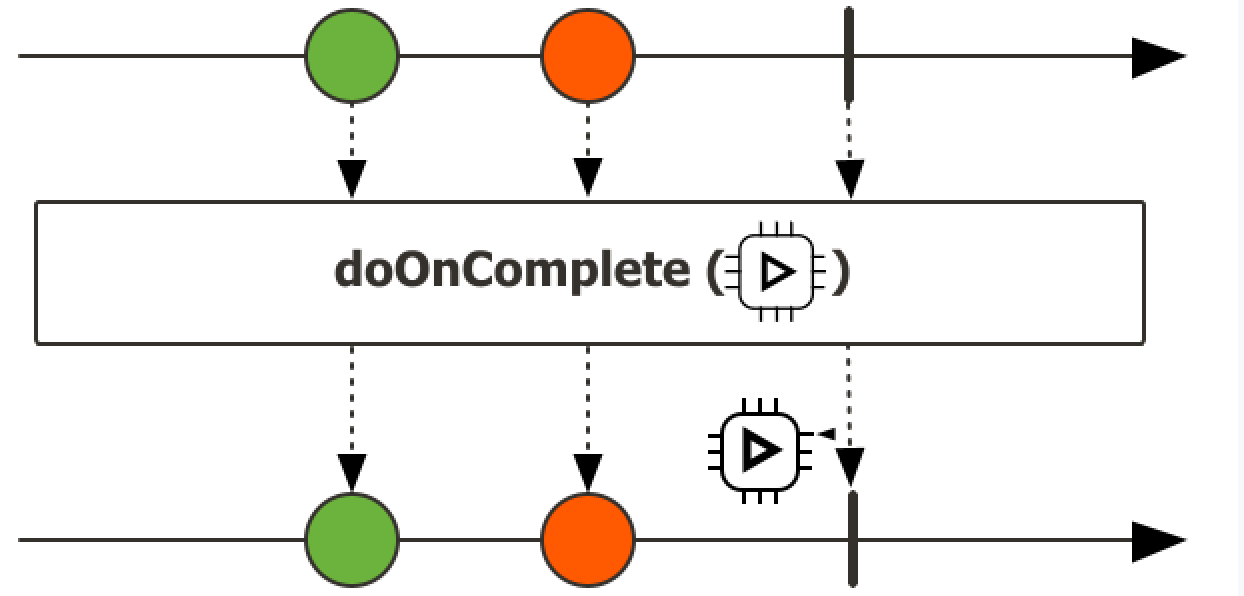
响应式编程学习笔记 响应式编程1、Reactor核心前置知识1、Lambda2、Function根据出参,入参分类1、有入参,有出参 --> FunctionFunction<String, Integer> function = a -> Integer.parseInt(a);2、有入参,无出参Consumer<String> consumer = a -> System.out.println(a);3、无入参,有出参Supplier<String> supplier = () -> UUID.randomUUID().toString();4、无入参,无出参Runnable runnable = () -> System.out.println("xixi"); 3、StreamAPI流式操作,三大步骤1、创建流Stream<Integer> integerStream = Stream.of(1, 2, 3); Stream<Integer> stream = list.stream();2、中间操作(intermediate operation),可以有多个filter,map,mapToInt,mapToLong,mapToDouble,flatMap,flatMapToInt,flatMapToLong,flatMapToDouble,mapMulti,mapMultiToInt,mapMultiToLong,mapMultiToDouble,peek...3、终止操作(terminal operation),只能有一个forEach,forEachOrdered,toArray,toArray,reduce,collect,toList,min,max,count,anyMatch,findFirst,findAny...流式操作是否并发? // 流的三大部份 // 1.创建流 2.N个中间操作 3.一个终止操作 Stream<Integer> integerStream = Stream.of(1, 2, 3); Stream<Object> buildStream = Stream.builder().add(1).add(2).add(3).build(); Stream<Object> concatStream = Stream.concat(integerStream, buildStream); Stream<Integer> stream = list.stream(); List<Integer> resultList = new ArrayList<>(); System.out.println("main线程: "+Thread.currentThread().getName()); // 流是不是并发操作? 答:默认单线程,可以通过parallel开启多线程,但是如果开启多线程,则需要自身注意线程安全问题 long count = list.stream() .parallel() // 开启多线程 并发流 .filter(i -> { // resultList.add(i); // 开启多线程,不能这样写,要保证流里面的数据是无状态的,即流里面的数据只在流内部使用 // 可以计算完成以后返回出去,但是不能在内部又引用外部的数据,可能会出现问题 System.out.println("filter线程: " + Thread.currentThread().getName()); return i > 2; }) .count(); System.out.println(resultList);注意: 要保证流里面的数据是无状态的中间操作:filter:过滤,挑出我们要的元素takeWhile示例List<Integer> collect = Stream.of(1, 2, 3, 4, 5, 6) .filter(a -> a > 2) // 无条件遍历 .toList(); System.out.println(collect); List<Integer> collect1 = Stream.of(1, 2, 3, 4, 5, 6) .takeWhile(a -> a < 2) // 当条件不满足时,直接返回 .toList(); System.out.println(collect1);map:映射,一对一映射mapToInt,MapToDouble..flatMap: 打散、散列、展开,一对多映射...终止操作:forEach、forEachOrdered、toArray、reduce、collect、toList、min、 max、count、anyMatch、allMatch、noneMatch、findFirst、findAny、iterator4、Reactive Stream目的:通过全异步的方式,加缓冲区构建一个实时的数据流系统。kafka,mq能构建大型的分布式响应系统,缺少本地化分布式响应系统方案jvm推出Reactive Stream,让所有异步线程能够互相监听消息,处理消息,构建实时消息处理流Api Component:1、Publisher:发布者2、Subscriber:订阅者3、Processor:处理器响应式编程总结:1、底层:基于数据缓冲队列+消息驱动模型+异步回调机制2、编码:流式编程+链式调用+生命式API3、效果:优雅全异步+消息实时处理+高吞吐量+占用少量资源与传统写法对比:传统写法痛点:以前要做一个高并发系统:缓存、异步、队列,手动控制整个逻辑现在:全自动控制整个逻辑Reactor1、快速上手介绍Reactor 是一个用于JVM的完全非阻塞的响应式编程框架,具备高效的需求管理(即对 “背压(backpressure)”的控制)能力。它与 Java 8 函数式 API 直接集成,比如 CompletableFuture, Stream, 以及 Duration。它提供了异步序列 API Flux(用于[N]个元素)和 Mono(用于 [0|1]个元素),并完全遵循和实现了“响应式扩展规范”(Reactive Extensions Specification)。Reactor 的 reactor-ipc 组件还支持非阻塞的进程间通信(inter-process communication, IPC)。 Reactor IPC 为 HTTP(包括 Websockets)、TCP 和 UDP 提供了支持背压的网络引擎,从而适合 应用于微服务架构。并且完整支持响应式编解码(reactive encoding and decoding)。依赖<dependencyManagement> <dependencies> <dependency> <groupId>io.projectreactor</groupId> <artifactId>reactor-bom</artifactId> <version>2023.0.0</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement><dependencies> <dependency> <groupId>io.projectreactor</groupId> <artifactId>reactor-core</artifactId> </dependency> <dependency> <groupId>io.projectreactor</groupId> <artifactId>reactor-test</artifactId> <scope>test</scope> </dependency> </dependencies>2、响应式编程响应式编程是一种关注于数据流(data streams)和变化传递(propagation of change)的异步编程方式。 这意味着它可以用既有的编程语言表达静态(如数组)或动态(如事件源)的数据流。3、核心特性1、Mono和FluxMono: 0|1 数据流Flux: N数据流响应式流:元素(内容) + 信号(完成/异常);2、subscribe()自定义流的信号感知回调.subscribe( System.out::println // 消费方法 , throwable -> System.out.println(throwable.getMessage()) // 感知异常 , () -> System.out.println("complete") // 感知正常结束 ); // 流只有被订阅了才会执行,否则没有任何操作自定义消费者.subscribe(new BaseSubscriber<String>() { // 自定义消费者 @Override protected void hookOnSubscribe(Subscription subscription) { System.out.println("被订阅"); requestUnbounded(); } @Override protected void hookOnNext(String value) { System.out.println("下个元素"); } @Override protected void hookOnComplete() { System.out.println("完成信号"); } @Override protected void hookOnError(Throwable throwable) { System.out.println("异常信号"); } @Override protected void hookOnCancel() { System.out.println("结束信号"); } @Override protected void hookFinally(SignalType type) { System.out.println("终止信号"); } });3、流的取消消费者调用 cancle() 取消流的订阅;4、自定义消费者推荐直接编写jdk自带的BaseSubscriber的实现类5、背压(back pressure)和请求重塑(reshape requests)buffer/** * 缓冲区 */ private static void bufferTest() { Flux.range(1, 10).buffer(3).subscribe(v -> System.out.println("v的类型:" + v.getClass() + "的值:" + v)); }limitRate/** * 测试limitRate */ private static void limitTest() { Flux.range(1,1000) .log() .limitRate(100) // 一次预取100个元素 75%预取策略,第一次取100个如果75%已经处理,继续请求新的75%数据 .subscribe(System.out::println); }6、以编程方式创建序列-SinkSink.nextSink.complete1、同步环境-generate/** * 通过generate创建序列 */ private static void generateTest() { List<Integer> list = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9); Flux.generate(() -> 0, // 初始值 (i, a) -> { a.next(list.get(i)); // 把元素放入通道 if (i == list.size() - 1) { a.complete(); // 完成 } return ++i; // 下次回调的元素 } ) .subscribe(System.out::println); }2、多线程-create/** * 通过create创建序列,create适用与多线程环境,generate适用于单线程环境 */ private static void createTest() { Flux.create(sink -> { for (int i = 0; i < 10; i++) { sink.next("2"); } }).subscribe(System.out::println); }7、handle自定义流中的处理规则/** * handle自定义处理 */ private static void handleTest() { Flux.range(1, 10) .handle((value,sink) -> { System.out.println("接收到value:" + value); sink.next("haha_" + value); }) .subscribe(); }8、自定义线程调度响应式:响应式编程: 全异步、消息、事件回调默认还是用当前线程,生成整个流、发布流、流操作/** * 自定义线程测试 */ private static void threadTest() { // 响应式编程:全异步,消息,回调机制 Schedulers.boundedElastic(); // 有界的,弹性线程池 Schedulers.single(); // 单线程 Schedulers.immediate(); // 都在同一个当前线程(默认) Scheduler scheduler = Schedulers.newParallel("my-parallel"); Flux<Integer> flux = Flux.range(1, 10) .publishOn(scheduler) .log(); flux.subscribe(); }9、异常处理命令式编程:常见的错误处理方式Catch and return a static default value. 捕获异常返回一个静态默认值try { return doSomethingDangerous(10); } catch (Throwable error) { return "RECOVERED"; }onErrorReturn: 实现上面效果,错误的时候返回一个值●1、吃掉异常,消费者无异常感知●2、返回一个兜底默认值●3、流正常完成;Catch and execute an alternative path with a fallback method.吃掉异常,执行一个兜底方法;try { return doSomethingDangerous(10); } catch (Throwable error) { return doOtherthing(10); }onErrorResume●1、吃掉异常,消费者无异常感知●2、调用一个兜底方法●3、流正常完成Flux.just(1, 2, 0, 4) .map(i -> "100 / " + i + " = " + (100 / i)).onErrorResume(err -> Mono.just("哈哈-777")) .subscribe(v -> System.out.println("v = " + v), err -> System.out.println("err = " + err), () -> System.out.println("流结束"));Catch and dynamically compute a fallback value. 捕获并动态计算一个返回值根据错误返回一个新值try { Value v = erroringMethod(); return MyWrapper.fromValue(v); } catch (Throwable error) { return MyWrapper.fromError(error); }.onErrorResume(err -> Flux.error(new BusinessException(err.getMessage()+":炸了")))●1、吃掉异常,消费者有感知●2、调用一个自定义方法●3、流异常完成Catch, wrap to a BusinessException, and re-throw.捕获并包装成一个业务异常,并重新抛出try { return callExternalService(k); } catch (Throwable error) { throw new BusinessException("oops, SLA exceeded", error); }包装重新抛出异常: 推荐用 .onErrorMap●1、吃掉异常,消费者有感知●2、抛新异常●3、流异常完成.onErrorResume(err -> Flux.error(new BusinessException(err.getMessage()+":炸了"))) Flux.just(1, 2, 0, 4) .map(i -> "100 / " + i + " = " + (100 / i)) .onErrorMap(err-> new BusinessException(err.getMessage()+": 又炸了...")) .subscribe(v -> System.out.println("v = " + v), err -> System.out.println("err = " + err), () -> System.out.println("流结束"));Catch, log an error-specific message, and re-throw.捕获异常,记录特殊的错误日志,重新抛出try { return callExternalService(k); } catch (RuntimeException error) { //make a record of the error log("uh oh, falling back, service failed for key " + k); throw error; }Flux.just(1, 2, 0, 4) .map(i -> "100 / " + i + " = " + (100 / i)) .doOnError(err -> { System.out.println("err已被记录 = " + err); }).subscribe(v -> System.out.println("v = " + v), err -> System.out.println("err = " + err), () -> System.out.println("流结束"));●异常被捕获、做自己的事情●不影响异常继续顺着流水线传播●1、不吃掉异常,只在异常发生的时候做一件事,消费者有感知Use the finally block to clean up resources or a Java 7 “try-with-resource” construct. Flux.just(1, 2, 3, 4) .map(i -> "100 / " + i + " = " + (100 / i)) .doOnError(err -> { System.out.println("err已被记录 = " + err); }) .doFinally(signalType -> { System.out.println("流信号:"+signalType); })忽略当前异常,仅通知记录,继续推进Flux.just(1,2,3,0,5) .map(i->10/i) .onErrorContinue((err,val)->{ System.out.println("err = " + err); System.out.println("val = " + val); System.out.println("发现"+val+"有问题了,继续执行其他的,我会记录这个问题"); }) //发生 .subscribe(v-> System.out.println("v = " + v), err-> System.out.println("err = " + err));10、常用操作filter、flatMap、concatMap、flatMapMany、transform、defaultIfEmpty、switchIfEmpty、concat、concatWith、merge、mergeWith、mergeSequential、zip、zipWith...2、Spring Webflux0、组件对比API功能Servlet-阻塞式WebWebFlux-响应式Web前端控制器DispatcherServletDispatcherHandler处理器ControllerWebHandler/Controller请求、响应ServletRequest、ServletResponseServerWebExchange:ServerHttpRequest、ServerHttpResponse过滤器Filter(HttpFilter)WebFilter异常处理器HandlerExceptionResolverDispatchExceptionHandlerWeb配置@EnableWebMvc@EnableWebFlux自定义配置WebMvcConfigurerWebFluxConfigurer返回结果任意Mono、Flux、任意发送REST请求RestTemplateWebClientMono: 返回0|1 数据流Flux:返回N数据流1、WebFlux底层基于Netty实现的Web容器与请求/响应处理机制参照:https://docs.spring.io/spring-framework/reference/6.0/web/webflux.html2、引入<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.1.6</version> </parent> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-webflux</artifactId> </dependency> </dependencies>Context 响应式上下文数据传递; 由下游传播给上游;以前: 浏览器 --> Controller --> Service --> Dao: 阻塞式编程现在: Dao(数据源查询对象【数据发布者】) --> Service --> Controller --> 浏览器: 响应式大数据流程: 从一个数据源拿到大量数据进行分析计算;ProductVistorDao.loadData() .distinct() .map() .filter() .handle().subscribe();;//加载最新的商品浏览数据3、Reactor Core1、HttpHandler、HttpServer** * 测试webflux * @author : jucunqi * @since : 2025/1/16 */ public class FluxMainApplication { public static void main(String[] args) throws IOException { HttpHandler handler = (ServerHttpRequest request, ServerHttpResponse response) -> { URI uri = request.getURI(); System.out.println(Thread.currentThread() + "请求进来: " + uri); //编写请求处理的业务,给浏览器写一个内容 URL + "Hello~!" // response.getHeaders(); //获取响应头 // response.getCookies(); //获取Cookie // response.getStatusCode(); //获取响应状态码; // response.bufferFactory(); //buffer工厂 // response.writeWith() //把xxx写出去 // response.setComplete(); //响应结束 //创建 响应数据的 DataBuffer DataBufferFactory factory = response.bufferFactory(); String result = "Hello world"; //数据Buffer DataBuffer buffer = factory.wrap(result.getBytes(StandardCharsets.UTF_8)); // 需要一个 DataBuffer 的发布者 return response.writeWith(Flux.just(buffer)); }; //2、启动一个服务器,监听8080端口,接受数据,拿到数据交给 HttpHandler 进行请求处理 ReactorHttpHandlerAdapter adapter = new ReactorHttpHandlerAdapter(handler); //3、启动Netty服务器 HttpServer.create() .host("localhost") .port(8080) .handle(adapter) //用指定的处理器处理请求 .bindNow(); //现在就绑定 System.out.println("服务器启动完成....监听8080,接受请求"); System.in.read(); System.out.println("服务器停止...."); } }4、DispatcherHandlerSpringMVC: DispatcherServlet;SpringWebFlux: DispatcherHandler1、请求处理流程HandlerMapping:请求映射处理器; 保存每个请求由哪个方法进行处理HandlerAdapter:处理器适配器;反射执行目标方法HandlerResultHandler:处理器结果处理器;SpringMVC: DispatcherServlet 有一个 doDispatch() 方法,来处理所有请求;WebFlux: DispatcherHandler 有一个 handle(ServerWebExchange exchange) 方法,来处理所有请求;public Mono<Void> handle(ServerWebExchange exchange) { if (this.handlerMappings == null) { return createNotFoundError(); } if (CorsUtils.isPreFlightRequest(exchange.getRequest())) { return handlePreFlight(exchange); } return Flux.fromIterable(this.handlerMappings) //拿到所有的 handlerMappings .concatMap(mapping -> mapping.getHandler(exchange)) //找每一个mapping看谁能处理请求 .next() //直接触发获取元素; 拿到流的第一个元素; 找到第一个能处理这个请求的handlerAdapter .switchIfEmpty(createNotFoundError()) //如果没拿到这个元素,则响应404错误; .onErrorResume(ex -> handleDispatchError(exchange, ex)) //异常处理,一旦前面发生异常,调用处理异常 .flatMap(handler -> handleRequestWith(exchange, handler)); //调用方法处理请求,得到响应结果 }1、请求和响应都封装在 ServerWebExchange 对象中,由handle方法进行处理2、如果没有任何的请求映射器; 直接返回一个: 创建一个未找到的错误; 404; 返回Mono.error;终结流3、跨域工具,是否跨域请求,跨域请求检查是否复杂跨域,需要预检请求;4、Flux流式操作,先找到HandlerMapping,再获取handlerAdapter,再用Adapter处理请求,期间的错误由onErrorResume触发回调进行处理;源码中的核心两个:handleRequestWith: 编写了handlerAdapter怎么处理请求handleResult: String、User、ServerSendEvent、Mono、Flux ...concatMap: 先挨个元素变,然后把变的结果按照之前元素的顺序拼接成一个完整流private <R> Mono<R> createNotFoundError() { Exception ex = new ResponseStatusException(HttpStatus.NOT_FOUND); return Mono.error(ex); } Mono.defer(() -> { Exception ex = new ResponseStatusException(HttpStatus.NOT_FOUND); return Mono.error(ex); }); //有订阅者,且流被激活后就动态调用这个方法; 延迟加载; 5、注解开发1、目标方法传参https://docs.spring.io/spring-framework/reference/6.0/web/webflux/controller/ann-methods/arguments.htmlController method argumentDescriptionServerWebExchange封装了请求和响应对象的对象; 自定义获取数据、自定义响应ServerHttpRequest, ServerHttpResponse请求、响应WebSession访问Session对象java.security.Principal org.springframework.http.HttpMethod请求方式java.util.Locale国际化java.util.TimeZone + java.time.ZoneId时区@PathVariable路径变量@MatrixVariable矩阵变量@RequestParam请求参数@RequestHeader请求头;@CookieValue获取Cookie@RequestBody获取请求体,Post、文件上传HttpEntity封装后的请求对象@RequestPart获取文件上传的数据 multipart/form-data.java.util.Map, org.springframework.ui.Model, and org.springframework.ui.ModelMap.Map、Model、ModelMap@ModelAttribute Errors, BindingResult数据校验,封装错误SessionStatus + class-level @SessionAttributes UriComponentsBuilderFor preparing a URL relative to the current request’s host, port, scheme, and context path. See URI Links.@SessionAttribute @RequestAttribute转发请求的请求域数据Any other argument所有对象都能作为参数:1、基本类型 ,等于标注@RequestParam 2、对象类型,等于标注 @ModelAttribute2、返回值写法sse和websocket区别:SSE:单工;请求过去以后,等待服务端源源不断的数据websocket:双工: 连接建立后,可以任何交互;Controller method return valueDescription@ResponseBody把响应数据写出去,如果是对象,可以自动转为jsonHttpEntity, ResponseEntityResponseEntity:支持快捷自定义响应内容HttpHeaders没有响应内容,只有响应头ErrorResponse快速构建错误响应ProblemDetailSpringBoot3;String就是和以前的使用规则一样;forward: 转发到一个地址redirect: 重定向到一个地址配合模板引擎View直接返回视图对象java.util.Map, org.springframework.ui.Model以前一样@ModelAttribute以前一样Rendering新版的页面跳转API; 不能标注 @ResponseBody 注解void仅代表响应完成信号Flux, Observable, or other reactive type使用 text/event-stream 完成SSE效果Other return values未在上述列表的其他返回值,都会当成给页面的数据;6、文件上传https://docs.spring.io/spring-framework/reference/6.0/web/webflux/controller/ann-methods/multipart-forms.htmlclass MyForm { private String name; private MultipartFile file; // ... } @Controller public class FileUploadController { @PostMapping("/form") public String handleFormUpload(MyForm form, BindingResult errors) { // ... } }现在@PostMapping("/") public String handle(@RequestPart("meta-data") Part metadata, @RequestPart("file-data") FilePart file) { // ... }7、错误处理 @ExceptionHandler(ArithmeticException.class) public String error(ArithmeticException exception){ System.out.println("发生了数学运算异常"+exception); //返回这些进行错误处理; // ProblemDetail: 建造者:声明式编程、链式调用 // ErrorResponse : return "炸了,哈哈..."; }8、自定义Flux配置 WebFluxConfigurer容器中注入这个类型的组件,重写底层逻辑@Configuration public class MyWebConfiguration { //配置底层 @Bean public WebFluxConfigurer webFluxConfigurer(){ return new WebFluxConfigurer() { @Override public void addCorsMappings(CorsRegistry registry) { registry.addMapping("/**") .allowedHeaders("*") .allowedMethods("*") .allowedOrigins("localhost"); } }; } }9、Filter@Component public class MyWebFilter implements WebFilter { @Override public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) { ServerHttpRequest request = exchange.getRequest(); ServerHttpResponse response = exchange.getResponse(); System.out.println("请求处理放行到目标方法之前..."); Mono<Void> filter = chain.filter(exchange); //放行 //流一旦经过某个操作就会变成新流 Mono<Void> voidMono = filter.doOnError(err -> { System.out.println("目标方法异常以后..."); }) // 目标方法发生异常后做事 .doFinally(signalType -> { System.out.println("目标方法执行以后..."); });// 目标方法执行之后 //上面执行不花时间。 return voidMono; //看清楚返回的是谁!!! } }3、R2DBC1、手写R2DBC用法:1、导入驱动: 导入连接池(r2dbc-pool)、导入驱动(r2dbc-mysql )2、使用驱动提供的API操作引入依赖<dependency> <groupId>io.asyncer</groupId> <artifactId>r2dbc-mysql</artifactId> <version>1.0.5</version> </dependency>手写代码public static void main(String[] args) throws IOException { // 创建mysql配置 MySqlConnectionConfiguration configuration = MySqlConnectionConfiguration.builder() .host("localhost") .port(3306) .username("root") .password("12345678") .database("test") .build(); // 获取mysql连接工厂 MySqlConnectionFactory factory = MySqlConnectionFactory.from(configuration); Mono.from( factory.create() .flatMapMany(conn -> conn .createStatement("select * from customers where customer_id = ?") .bind(0, 1L) .execute() ).flatMap(result -> result.map(readable -> { return new Customers(((Integer) readable.get("customer_id")), Objects.requireNonNull(readable.get("customer_name")).toString()); })) ).subscribe(System.out::println); System.in.read(); }2、Spring Data R2DBC提升生产力方式的 响应式数据库操作0、整合1、导入依赖 <!-- https://mvnrepository.com/artifact/io.asyncer/r2dbc-mysql --> <dependency> <groupId>io.asyncer</groupId> <artifactId>r2dbc-mysql</artifactId> <version>1.0.5</version> </dependency> <!-- 响应式 Spring Data R2dbc--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-r2dbc</artifactId> </dependency>2、编写配置spring: r2dbc: password: 123456 username: root url: r2dbc:mysql://localhost:3306/test name: test3、@Autowired private R2dbcEntityTemplate template; /** * 测试template // 适合单表操作,复杂sql不好编写 * @throws IOException io异常 */ @Test public void springDataR2dbcTest() throws IOException { // 1. 构建查询条件 Criteria criteria = Criteria .empty() .and("project_leader") .is("1"); // 构建Query对象 Query query = Query .query(criteria); // 查询数据 template.select(query, com.jcq.r2dbc.eneity.Test.class) .subscribe(test -> System.out.println("test = " + test)); System.out.println(System.in.read()); } @Autowired private DatabaseClient databaseClient; /** * 测试databaseClient // 更底层,适合复杂sql 比如join */ @Test public void databaseClientTest() throws IOException { databaseClient.sql("select * from test where id in (?,?)") .bind(0, 1) .bind(1, 2) .fetch() // 抓取数据 .all() // 抓取所有数据 .map(a -> new com.jcq.r2dbc.eneity.Test(((Integer) a.get("id")),a.get("project_leader").toString())) .subscribe(a -> System.out.println("a = " + a)); System.out.println(System.in.read()); }1、声明式接口:R2dbcRepositoryRepository接口@Repository public interface TAutherRepository extends R2dbcRepository<TAuther,Long> { // 根据命名实现sql Flux<TAuther> findAllByIdAndNameLike(Long id,String name); @Query("select * from t_author") Flux<TAuther> queryList(); } 自定义Converter@ReadingConverter // 读取数据库的时候,吧row转成 TBook public class TBookConverter implements Converter<Row, TBook> { @Override public TBook convert(Row source) { TBook tBook = new TBook(); tBook.setId((Long) source.get("id")); tBook.setTitle((String) source.get("title")); tBook.setAuthorId((Long) source.get("author_id")); Object instance = source.get("publish_time"); System.out.println(instance); ZonedDateTime instance1 = (ZonedDateTime) instance; tBook.setPublishTime(instance1.toInstant()); TAuther tAuther = new TAuther(); tAuther.setName(source.get("name", String.class)); tBook.setTAuther(tAuther); return tBook; } }配置生效@Configuration public class R2DbcConfiguration { @Bean @ConditionalOnMissingBean public R2dbcCustomConversions r2dbcCustomConversions() { return R2dbcCustomConversions.of(MySqlDialect.INSTANCE, new TBookConverter()); } } 3、编程式组件R2dbcEntityTemplateDatabaseClient4、最佳实践最佳实践: 提升生产效率的做法1、Spring Data R2DBC,基础的CRUD用 R2dbcRepository 提供好了2、自定义复杂的SQL(单表): @Query;3、多表查询复杂结果集: DatabaseClient 自定义SQL及结果封装;@Query + 自定义 Converter 实现结果封装经验:1-1:1-N 关联关系的封装都需要自定义结果集的方式Spring Data R2DBC:自定义Converter指定结果封装DatabaseClient:贴近底层的操作进行封装; 见下面代码MyBatis: 自定义 ResultMap 标签去来封装databaseClient.sql("select b.*,t.name as name from t_book b " + "LEFT JOIN t_author t on b.author_id = t.id " + "WHERE b.id = ?") .bind(0, 1L) .fetch() .all() .map(row-> { String id = row.get("id").toString(); String title = row.get("title").toString(); String author_id = row.get("author_id").toString(); String name = row.get("name").toString(); TBook tBook = new TBook(); tBook.setId(Long.parseLong(id)); tBook.setTitle(title); TAuthor tAuthor = new TAuthor(); tAuthor.setName(name); tAuthor.setId(Long.parseLong(author_id)); tBook.setAuthor(tAuthor); return tBook; }) .subscribe(tBook -> System.out.println("tBook = " + tBook));