


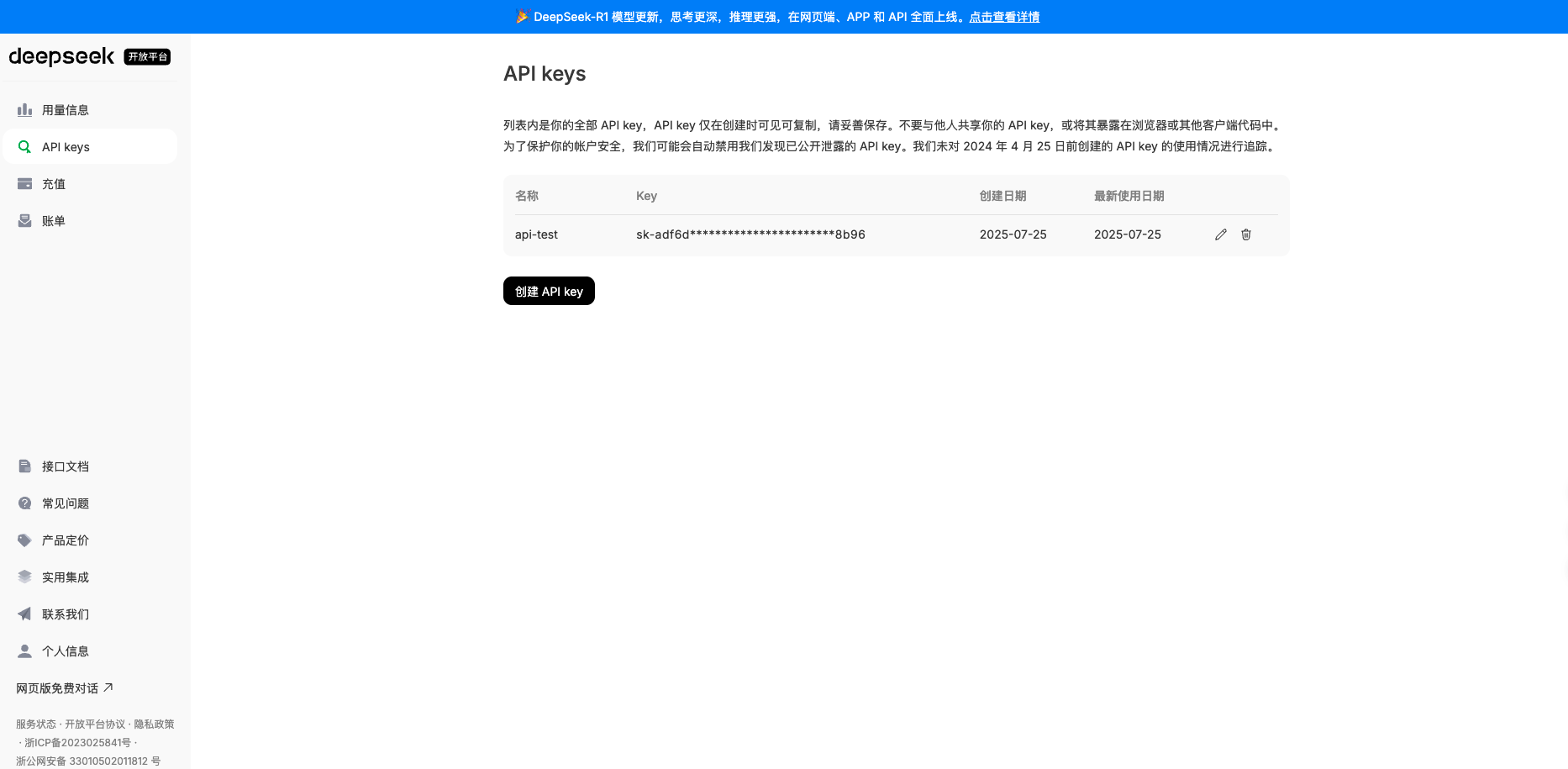
最近在调用大模型时,遇到了一个十分棘手的怪象——模型输出陷入“死循环”,不停重复相同内容,像一台复读机,如下图所示。

为了解决这个问题,我查阅了相关资料,梳理出大模型重复输出的现象分级、核心原因以及可解决办法,整理成文分享给大家,帮大家快速摆脱“复读机”困扰。
一、现象分级:大模型“复读”分3种
大模型的重复输出并非单一情况,根据重复的范围和程度,可分为以下3个级别,大家可以对照判断自己遇到的情况:
- 词汇/短语级重复:最基础的重复形式,模型生成的文本中,同一个词语、短语或短句反复出现,比如一句话在同一段落中被多次复制粘贴,阅读起来十分冗余。
- 段落级重复:当生成较长文本(如文章、方案)时,模型可能生成重复的句子群或完整段落,甚至出现与前文几乎完全一致的内容段,严重影响内容的完整性和可读性。
- 内容结构级重复:针对结构化回答需求(如分点解析、步骤说明),模型可能多次使用相似的结构、句式进行解释,虽然核心内容略有差异,但整体框架重复,显得拖沓且缺乏新意。
二、核心原因:3大因素导致模型“卡壳复读”
1. 提示词问题(最常见,占比最高)
- 需求提示不清晰:如果给模型的提示过于模糊、笼统,没有明确回答方向、范围或要求,模型无法精准捕捉需求,就会通过重复内容“凑数”,形成冗余输出。
- 上下文缺失:模型的回答依赖上下文信息,如果提问时没有提供足够的背景、前提,或对话过程中上下文断裂,模型无法理解需求的核心,就容易陷入重复循环。
2. 模型参数设置不合理
- 温度(temperature)设置过低:温度值控制模型输出的随机性,当温度设置过低(如0),模型会生成保守、确定的内容,倾向于重复高概率词汇和句式,进而出现重复。
- Top-k/Top-p采样策略不当:这两个参数用于控制模型选择词汇的范围,若设置不合理,会导致模型只能选择少数高概率词汇,无法生成多样化内容,最终陷入重复。
3. 模型本身的局限性
最终的输出内容由大模型的核心算法、参数配置和训练数据决定。如果模型本身存在训练不充分、参数优化不足等问题,也可能导致其在生成内容时,容易出现重复输出的情况。
三、解决办法:对症施策,快速解决“复读”问题
针对上述原因,整理了可直接落地的解决办法,从易到难,大家可以按需尝试,基本能解决80%以上的重复输出问题:
1. 优化提示词
- 明确禁止重复:在提示词中直接添加“禁止输出重复信息”“避免重复句式和内容”等要求,直接约束模型的输出行为。
- 丰富上下文:补充足够的背景信息、前提条件,或在对话中逐步递进提问,让模型清晰理解需求,避免因信息不足导致重复。
- 细化需求+拆分问题:将模糊的需求拆解成更小的子问题,明确每个问题的回答方向(如“从3个不同角度解析XX”“分步骤说明XX”),引导模型生成多样化内容。
2. 调整模型参数
- 调整temperature:将温度值设置在0.7-0.9之间,这个区间既能保证输出内容的准确性,又能增加随机性,鼓励模型生成更多不同的内容,避免重复。
- 优化Top-p采样:适当调整Top-p的值(通常设置在0.9左右),扩大模型选择词汇的范围,让模型有更多创作空间,减少重复概率。
评论 (0)